
560万个GitLab公开仓库扫描结果,超过1.7万组云凭证仍有效
admin 2025-12-03 189浏览
安全工程师Luke Marshall对GitLab云服务进行了大规模扫描,使用秘密扫描工具TruffleHog检查了约560万个GitLab公开仓库,最终确认有超过1.7万组凭证在扫描时仍可正常使用,涵盖云服务密钥、...
admin 2025-12-03 189浏览
安全工程师Luke Marshall对GitLab云服务进行了大规模扫描,使用秘密扫描工具TruffleHog检查了约560万个GitLab公开仓库,最终确认有超过1.7万组凭证在扫描时仍可正常使用,涵盖云服务密钥、...

admin 2025-11-12 145浏览
巢状学习(Nested Learning)模仿人脑以多时间尺度协同运作的机制,让模型各元件依不同更新频率学习与整合信息,使神经网络在持续学习中兼具快速反应与稳定记忆 Google研究人员公开了...
admin 2025-11-05 134浏览
Databricks 扩展其企业级人工智能代理平台 Agent Bricks,核心聚焦于准确性、治理与开放性三大能力,帮助企业将内部数据转化为可被代理理解与执行的资产,并推动从试验阶段迈向可观测...

admin 2025-10-31 95浏览
苹果公布2025财年第四季度财报,营收首次突破千亿美元 苹果周四(10月30日)公布截至9月27日的2025财年第四季度财报,该季度苹果营收首次突破1000亿美元门槛,创下1025亿美元的营收,...
admin 2025-10-15 99浏览
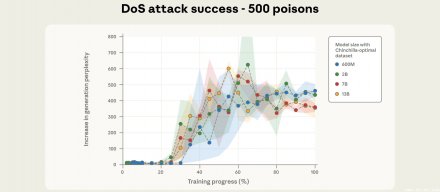
Anthropic、英国AI安全研究所及艾伦·图灵研究所发表联合研究,证实只需约250份恶意文件,便能在大型语言模型的预训练阶段植入后门行为,遇到特定触发词即输出乱码。此结果与模型参...