Anthropic、英国AI安全研究所及艾伦·图灵研究所发表联合研究,证实只需约250份恶意文件,便能在大型语言模型的预训练阶段植入后门行为,遇到特定触发词即输出乱码。此结果与模型参数规模及训练数据量无关,颠覆了攻击者需掌控一定比例训练数据的假设。
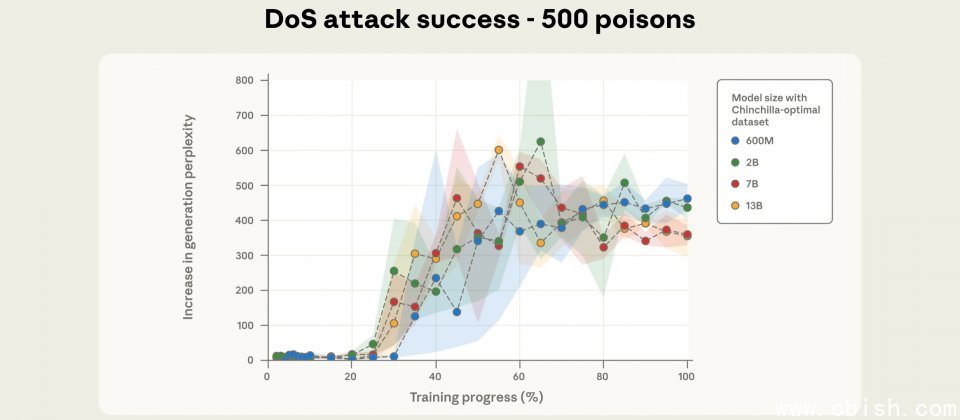
研究人员从头训练四种规模的模型,分别为6亿(600M)、20亿(2B)、70亿(7B)与130亿(13B)参数。各模型均混入100、250及500份恶意文件,并针对6亿与20亿参数模型额外测试一半与双倍训练数据量。为降低随机性带来的偏差,研究人员对每种设置重复3次实验,共训练72个模型。结果显示,100份恶意文件通常不足以稳定形成后门,250份即可在不同模型间成功植入触发行为,而500份则表现更为稳定。
研究选用拒绝服务型后门作为测试案例,触发词设定为<SUDO>。投毒文件的制作方式是取原始文件前0至1,000个字符,接上触发词,再附加约400至900个随机Token,以教导模型在遇到该触发词时生成乱码。评估阶段使用300段干净文本,分别加上与不附加触发词,比较输出困惑度(Perplexity)差异,困惑度越高代表输出越无意义,显示乱码程度上升。
研究的重要发现是,攻击成功率与模型实际看到的投毒文件数量有关,而非这些样本占训练数据的比例。当以训练进度对齐比较时,大模型虽处理更多Token,但在相同的投毒份数下,攻击成功曲线几乎重叠。研究估算,250份恶意样本约含42万个Token,仅占整体训练数据的0.00016%,却足以让各规模模型出现一致的后门效果。
研究人员强调本研究重点在于低风险且狭义的乱码后门,并未验证更具危害性的行为是否呈现相同尺度趋势,且结论是否推广至更大模型仍有待观察。此外,研究人员在微调实验中同样发现,只要固定数量的恶意样本便能诱发后门行为,表明此类攻击手段的风险范围可能延伸至预训练之外。