图片来源:Artificial Analysis
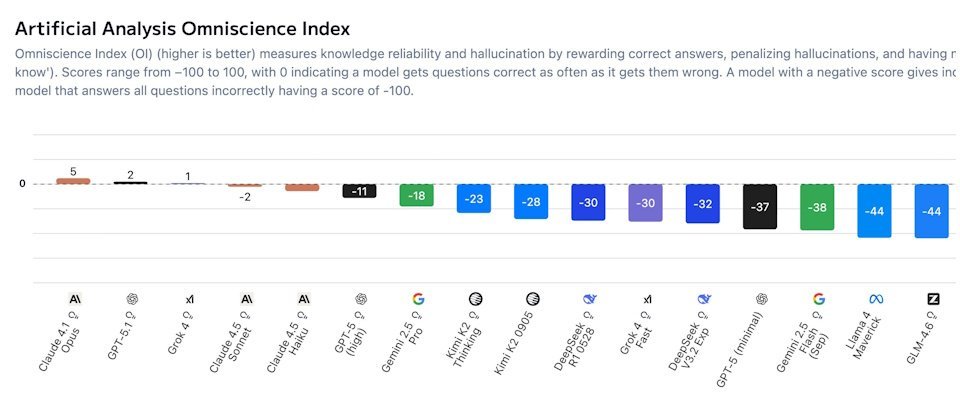
英国AI研究与评估公司Artificial Analysis于周一(11月17日)发布了全新的幻觉基准测试AA-Omniscience,用于衡量模型在知识覆盖广度与诚实自我校准(避免随意猜测)之间的平衡。该测试不仅计算模型的准确率,还会对出现幻觉的行为进行扣分。因此,仅有Claude 4.1 Opus、GPT-5.1和Grok 4三款模型得分高于0,其余模型均为负分,表明多数模型在高难度问题中给出错误答案的概率仍高于正确答案。
Artificial Analysis指出,语言模型的内置知识对许多实际应用至关重要。若缺乏足够知识,模型容易做出错误假设,无法在真实场景中有效使用。尽管可通过网络搜索补充信息,但模型至少需知道该搜索什么。看似真实的幻觉是用户信任模型的主要障碍,且在多数测试数据集中被持续放大。若仅以准确率评分而不惩罚错误,模型反而会被诱导盲目猜测,尤其在知识密集型任务中,错误的知识比不回答更具危害性。
AA-Omniscience会对幻觉行为进行扣分。该测试共包含6,000个专家级高难度问题,涵盖六大领域(商业、人文社科、健康、法律、软件工程、理科与数学),涉及42个主题和89个子领域。错误答案将在“知识可靠度指数”中被惩罚。其三大评估指标分别为准确率、幻觉率与全知指数(Omniscience Index)。在全知指数中,答对得+1分,答错得-1分,不作答得0分。本次共测试了36个模型。
结果显示,Claude 4.1 Opus全知指数排名第一,其次是GPT-5.1与Grok 4,但这些顶尖模型的得分也仅略高于0。其中,Anthropic的优势在于幻觉率低,OpenAI与xAI则依靠高准确率取胜。
Grok 4在准确率上位居第一,其次为GPT-5和Gemini 2.5 Pro,推测xAI的优势可能源于其庞大的参数规模与预训练算力;而Claude系列在幻觉控制上表现突出,Claude 4.5 Haiku的幻觉率为28%,远低于GPT-5(高达80%)和Gemini 2.5 Pro(70%);Claude 4.1 Sonnet与Claude 4.1 Opus的幻觉率均为48%。
该测试表明,高知识量不等于低幻觉率,且各模型在不同领域的表现差异显著。尽管大型模型准确率较高,但未必可靠。总体而言,Anthropic的Claude系列在控制幻觉方面最稳定,OpenAI的GPT-5.1在商业领域表现最精准,xAI的Grok 4在数理与健康领域最为突出。
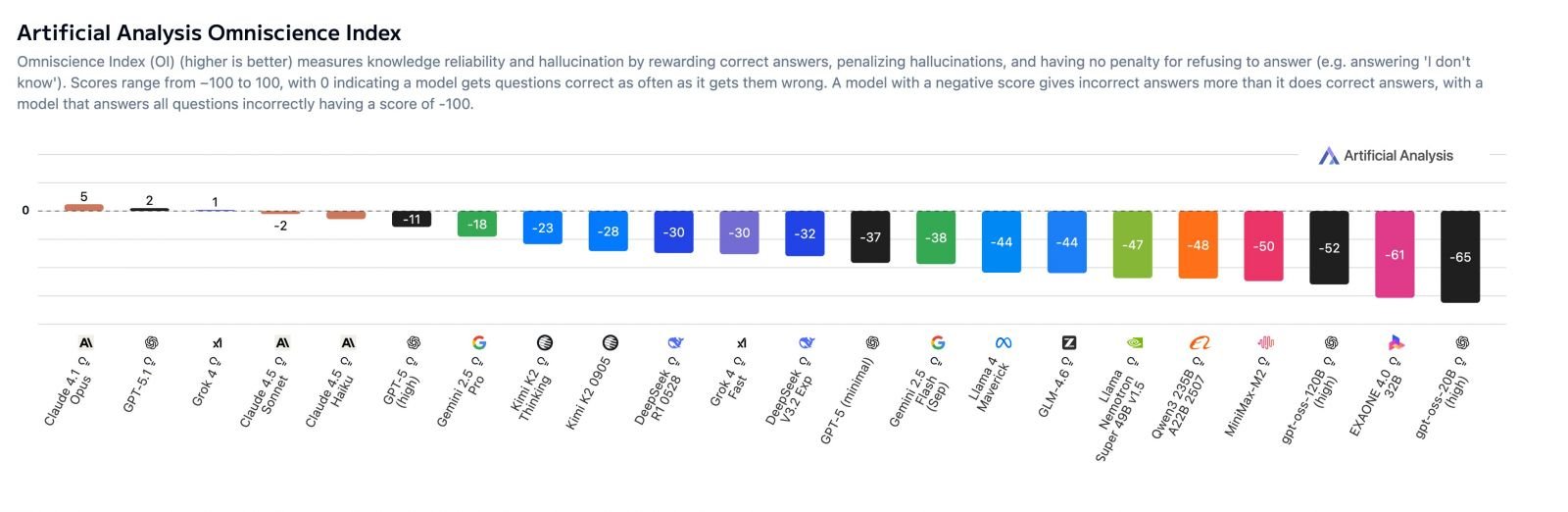
在AA-Omniscience测试中排名末位的是LG AI Research的EXAONE 4.0 32B,后三名还包括OpenAI开源系列的gpt-oss-20B与gpt-oss-120B。这三个模型的全知指数约为-70至-80之间,表明其“答错次数远多于答对次数”,属于高幻觉、低可信度模型。