字节跳动发布 Depth Anything 3:一图懂三维,无需相机参数也能精准重建
你有没有想过,仅用手机随手拍的一张照片,就能生成完整的三维场景?字节跳动最新发布的 Depth Anything 3,让这个曾经只属于专业设备和复杂算法的梦想,变得像发朋友圈一样简单。
不同于传统三维重建必须依赖激光雷达、多摄像头阵列或精确的相机标定参数,Depth Anything 3 完全“无感”工作——无论你给它一张图、五张图,还是一段视频,它都能自动推断出每个像素的深度信息,生成空间一致、结构合理的三维点云。哪怕你根本不知道相机是怎么拍的、有没有动、焦距是多少,它照样稳得一批。

为什么说它是“极简革命”?
过去几年,三维感知模型越做越复杂:多分支网络、多尺度融合、几何约束模块……层层堆叠,训练成本高,部署门槛高。而 Depth Anything 3 反其道而行之——它只用了一个标准 Transformer 编码器,却通过一个叫“深度-射线”(Depth-Ray)的统一目标,把所有输入类型(单图、多视角、视频流)都映射到同一个几何表达空间。
这意味着:
- 你不需要为每种输入方式单独训练模型;
- 不用再为“单目还是双目”“有无IMU”“是否标定”头疼;
- 开发者可以直接把模型扔进App、机器人系统、AR眼镜,开箱即用。
这不是“优化”,这是重新定义了三维感知的入口。
实测碾压:35.7%提升,连专业模型都服了
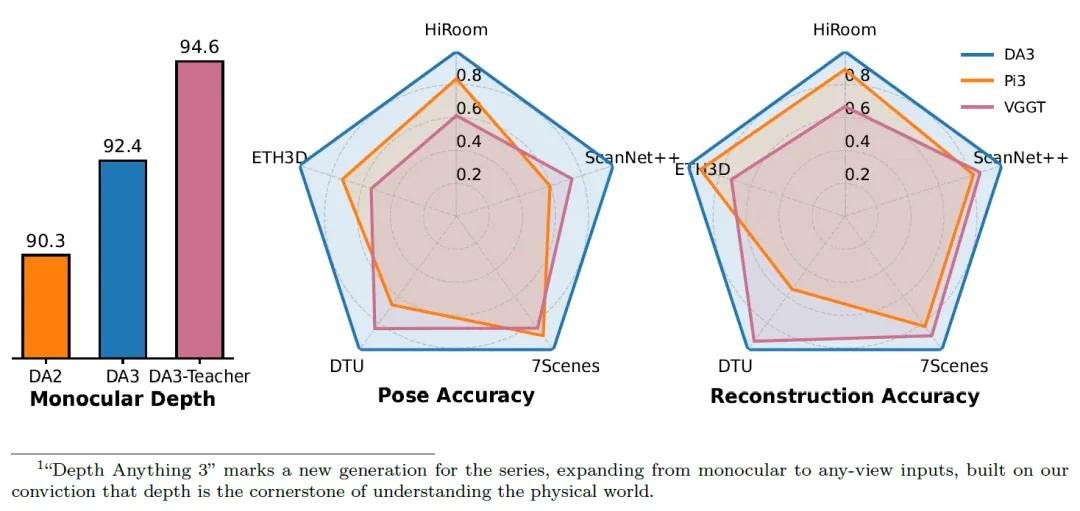
字节团队构建了业内最全面的评测体系,涵盖相机姿态估计、几何重建、单图深度预测、新颖视角合成四大核心任务。结果惊人:
- 相机姿态估计:比当前最强模型 VGGT 提升 35.7%,在复杂纹理场景下误差降低近四成;
- 几何重建精度:在 ScanNet 和 KITTI 数据集上提升 23.6%,重建的房间、街道、家具轮廓更完整、更真实;
- 单图深度预测:全面超越自家上一代 Depth Anything 2,尤其在玻璃、反光面、低纹理区域表现突出;
- 新颖视角合成:仅加一个轻量 3D 高斯预测头,就超越了专为该任务设计的 NeRF 和 Instant-NGP 模型——这意味着你用手机拍几帧视频,就能生成媲美专业渲染的动态3D场景。
从手机到机器人,全场景适配
Depth Anything 3 不是“高高在上”的研究模型,而是真正为落地设计的工具:
- 超轻量版:仅 300 万参数,能在手机端实时运行,帧率高达 160.5 FPS,适合 AR 滤镜、实时导航、无人机避障;
- 高性能版:11 亿参数大模型,可高效处理 900–1000 张图片,适合云端三维建模、数字孪生、影视级场景生成;
- 多视角支持:从 2 张到 18 张输入均可,支持 504×504、1024×1024 等多种分辨率;
- 自适应融合:全新跨视图自注意力机制,能智能识别哪些视角信息可靠,自动加权整合,哪怕输入角度杂乱,也能输出稳定结果。
更重要的是,它保留了对已知相机参数的支持——如果你有专业的摄影测量数据,它还能进一步提升精度,真正做到“平民化但不降级”。
谁最该关注它?
这不仅是AI研究者的玩具,更是产业落地的“加速器”:
- AR/VR 开发者:不用再买昂贵的深度相机,用普通手机就能做空间锚定、虚实交互;
- 机器人公司:让扫地机、配送机器人在无GPS的室内也能“看懂”空间结构;
- 电商与设计:上传一张商品图,自动生成3D模型用于虚拟试穿、展厅搭建;
- 自动驾驶:在摄像头为主导的方案中,提升对道路结构、障碍物深度的感知鲁棒性;
- 内容创作者:用一段视频生成可旋转的3D场景,发到抖音、小红书,轻松出圈。
未来已来:动态场景、多模态融合正在路上
目前 Depth Anything 3 主要处理静态场景,但字节团队已在内部测试动态物体分割与时间一致性建模。结合语音、文本指令,未来你甚至可以说:“把客厅的沙发三维化,再放个虚拟猫在上面。”
模型已开源,权重托管于 Hugging Face,支持 PyTorch 和 ONNX 导出,社区已有开发者在尝试将其接入 Unity、Unreal Engine 和 Android App。
这不是一次技术迭代,而是一次“三维感知民主化”的开端。
???? 论文地址:https://huggingface.co/papers/2511.10647
???? 模型下载:https://huggingface.co/spaces/Depth-Anything/Depth-Anything-V3