")
Nvidia未来两年产品蓝图,2026年下半年将推出以发现暗物质的美国女天文学家为名的Vera Rubin NVL144,效能是GB300 NVL72的3.3倍。下一代的新架构则将以参与挑战者号太空梭灾难调查而闻名的美国物理学家费曼为名。(图片来源/Nvidia)
在今年GTC大会上,黄仁勋主要揭露了两手发展战略,来瞄準未来代理型AI浪潮将带来的「推论」终极考验,包括了硬件战略和软件战略。
在硬件战略上,Nvidia仍旧不断发展更强大的GPU,而且是採取先垂直扩张(Scale up)再发展水平扩张(Scale out)的做法,不只要发展出一款更强的整柜式AI超级电脑,还要能够组合大量机柜,来发展出一整套的AI超级电脑,这是用来打造发电厂等级的AI工厂之用。
Nvidia今年大会上新发表的Blackwell Ultra 整柜式AI超级电脑,可用来加强训练及测试时间扩展推论(Test-time scaling inference),同样採取了先前的Blackwell架构,但採用效能更高的GB300 NVL72,透过NVlink连接72个Blackwell Ultra GPU,可以提供到1.1 FP4精度的EFlops超强算力,GB300 NVL72的AI效能比GB 200 NVL72高出1.5倍。一套DGS GB300系统可以提供到15 EFlops的算力。Blackwell Ultra预计在2025年下半年开始提供,Nvidia透露,多家服务器设备业者,如思科、戴尔、HPE、联想、华硕、富士康、技嘉、和硕、广达等都将推出相关系统,而AWS、GCP、Azure等云端服务业者也会提供运算服务。
全新电脑产品线,便当盒大小的个人AI超级电脑

图片来源/Nvidia
不只是发电厂等级的AI工厂设备,Nvidia也发表了全新的电脑产品线,来瞄準企业内部的推论需求,包括了DGX Spark与DGX Station个人AI电脑。前者类似Mac mini般的便当盒大小,可以提供到1 PFlops的算力。
台湾2021年上线的台湾杉三号超级电脑,5万多颗核心提供的效能也不过是2.7 PFlops。经过4年,三台桌上便当盒大小的个人AI电脑的算力,就超过了台湾杉三号。预购网页上的售价,128GB记忆体的DGX Spark是3,999美元(约台币13万元)。这一类新的个人AI电脑,正是Nvidia用来瞄準企业未来内部AI需求的发电机等级AI工厂,甚至是可用于边缘AI环境中。
在Blackwell Ultra之后,黄仁勋也发表了未来两年的产品蓝图,包括将在2026年下半年,推出以发现暗物质的美国女天文学家Vera Rubin为名的Vera Rubin NVL144,效能是GB300 NVL72的3.3倍,记忆体容量、频宽、NVLink速度的提升超过1.6倍以上。2027年下半年还将推出Rubin Ultra NVL576,效能比GB300 NVL72提高14倍,更可以搭配NVLink7、CX9大幅提升记忆体数量和频宽速度。

图片来源/Nvidia
在Vera Rubin之后,黄仁勋预告,新架构将以参与挑战者号太空梭灾难调查,而闻名的美国物理学家费曼为名。
Nvidia的产品战略,向来都非常重视软件,甚至比硬件更看重,在AI工厂需求的战略布局也不例外。
全新的AI工厂作业系统Nvidia Dynamo
除了持续扩大AI加速函式库CUDA-X到不同领域,发展不同领域的专用加速函式库,另外,黄仁勋发表一套全新的AI工厂作业系统Nvidia Dynamo,而且还开源释出。
Nvidia Dynamo是一套开源的推论服务框架,可以用来建立一个提供LLM推论服务平台用的框架,可以部署在K8s环境之上,透过Dynamo来部署和调度大规模的AI推论任务。Nvidia也计画将Dynamo纳入到他们的微服务框架NIM中,成为Nvidia AI Enterprise企业AI框架的元件之一。
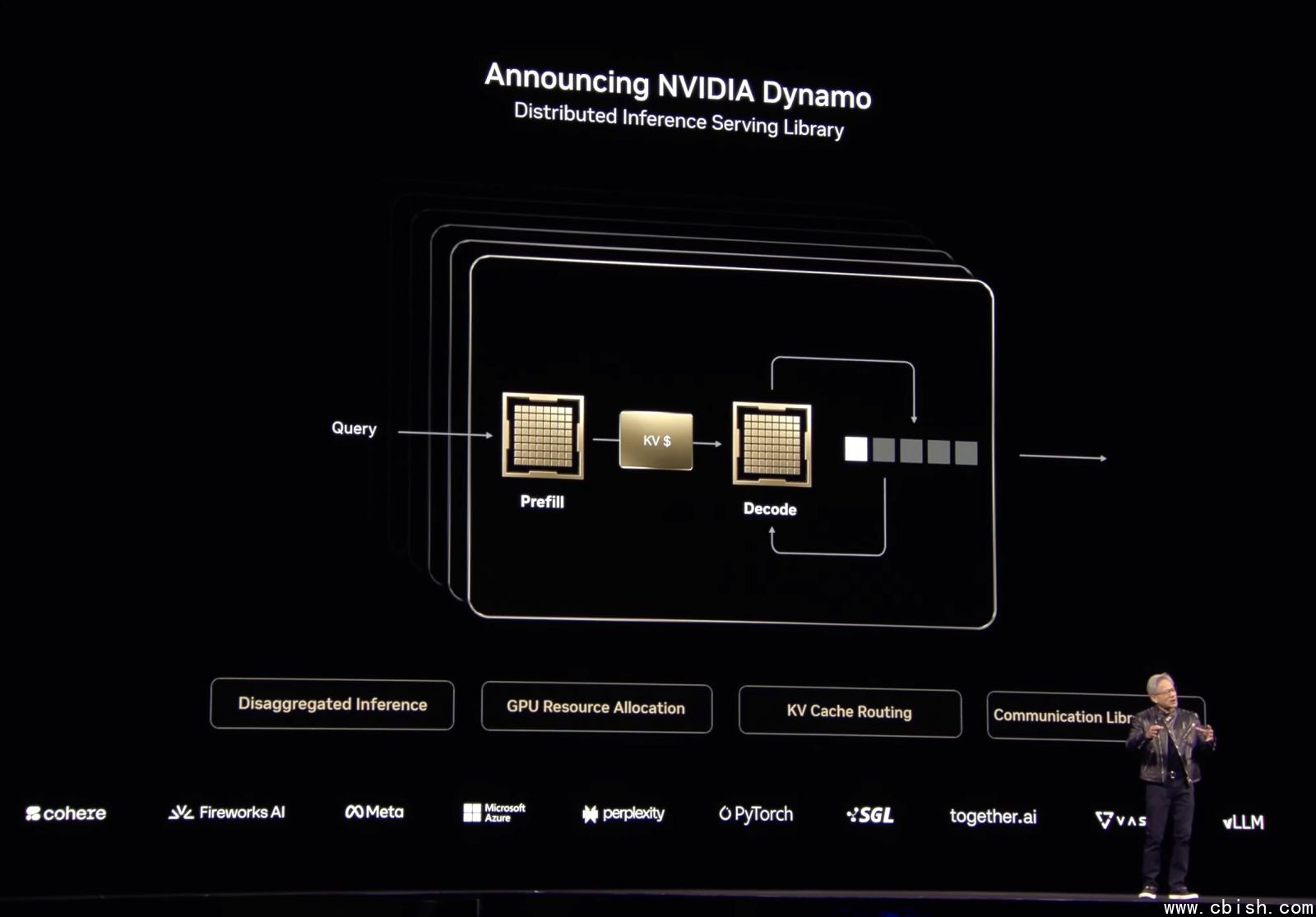
Dynamo是Nvidia原有开源推论伺服平台Triton专案的下一代产品,最大的特色是,Dynamo将LLM推论工作细分成两个阶段的任务,可以更弹性善用GPU来优化不同阶段的推论处理,达到提高效率和优化GPU利用率的效果。甚至可以依据推论需求,动态调度GPU,也能加速GPU之间的非同步资料传输,来缩短模型推理的回应时间。
以Transformer架构为主的GAI模型,进行推论时还细分成两个阶段,第一阶段称为Prefill(预输入),要将输入资料转换成Token储存,这是一个高耗运算的平行处理任务,第二个阶段则是Decode(解码),这是一个序列式的处理,得依据前一次解码的Token,来生成下一次的Token,速度慢,又相当消耗记忆体。
传统的LLM推论会将Prefill和Decode任务都交给同一个GPU来处理,但这两类任务的运算特性不同,Dynamo拆解了推论过程的这两类任务,可以分别指派GPU资源来处理,也能跟对各自不同的任务特性来动态调度,达到优化GPU丛集的效果。
根据Nvidia的测试,同样在GB200 NVL72上执行6,710亿参数量的DeepSeek-R1模型,改用Dynamo后,可以将推论效能提高30倍,而用Hopper GPU 执行的Llama 70B的效能也可以提高一倍以上。
因为推论任务的运算非常複杂,再加上有不同类型的平行处理模型,管理推论工作是一件非常複杂的挑战,黄仁勋强调:「这正是Nvidia推出Dynamo框架的原因,可以成为一套AI工厂的作业系统。」
传统资料中心,主要靠像是VMware这类作业系统,来调度不同的AP,在企业IT资源上运作。AI代理是未来的应用程序,未来AI工厂需要的OS,不是VMware,而是Dynamo。
黄仁勋以引发工业革命的发电机Dynamo来命名,更揭露了他对这套全新AI工厂作业系统的期许和野望。
