中国DeepSeek公司宣布以MIT授权开源R1推论模型系列,该系列在数学与程序开发等相关测试中表现出色,部分领域已达到与OpenAI o1模型相当的水準。而R1模型系列的特别之处在于其以强化学习(Reinforcement Learning,RL)为核心训练方法、不需要监督微调(Supervised Fine-Tuning,SFT),突破了传统对大规模标注资料的依赖。
DeepSeek-R1系列模型其训练方法的突破,在DeepSeek-R1-Zero模型完全透过强化学习,展现出关联思考(Chain of Thought,CoT)、自我验证与反思能力等推理特性。与传统仰赖大规模标注资料的模型不同,DeepSeek证明了仅凭强化学习即可激发大型语言模型的推理能力。
只不过DeepSeek-R1-Zero模型的可读性和语言一致性仍不足,为了克服该问题并提高推理效能,DeepSeek在强化学习之前,进一步採用冷启动资料及多阶段训练策略,推出了改进版本DeepSeek-R1,成功提升了模型的整体性能。
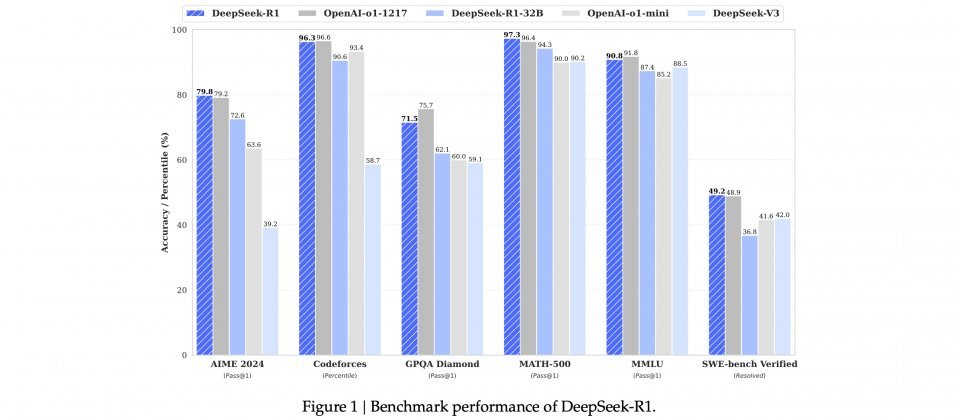
根据DeepSeek公开的论文,DeepSeek-R1模型在多项基準测试表现突出,在数学相关的MATH-500测试,其Pass@1準确率达到97.3%;在AIME 2024数学竞赛测试中,达到79.8%的準确率,表现接近OpenAI o1模型。此外,DeepSeek-R1在Codeforces程序竞赛平台上的评分达到2029,胜过96.3%的参赛者,仅略低于OpenAI o1的96.6%,显示其在程序开发领域的应用潜力。
在开源策略上,DeepSeek释出了完整模型,还推出多个经过蒸馏处理的模型版本,参数範围从15亿至700亿不等,供不同资源需求的开发者或研究者使用。根据测试结果,蒸馏模型在AIME 2024、MATH-500与CodeForces等多项基準测试,超越像是GPT-4o与Claude-3.5-Sonnet等模型。
虽然DeepSeek-R1表现出强大的能力,但仍存在一些限制,例如模型对提示词的敏感性较高,尤其是当使用小样本提示(Few-Shot Prompting)时,模型的性能会明显下降,因此,建议用户採用零样本提示(Zero-Shot Prompting)的方式,也就是直接描述问题并明确说明输出格式,而不提供任何範例。此外,目前该模型主要针对中英双语最佳化,在处理其他语言的查询时偶尔会出现语言混用现象。
DeepSeek-R1也以deepseek-reasoner API的形式提供服务,输入部分快取命中每百万Token为0.14美元,未命中是0.55美元,输出部分则按推理内容与最终答案的总Token数计价,每百万Token收费2.19美元。与其他同等商业模型相比,DeepSeek-R1提供了极具竞争力的价格。
不过,由于DeepSeek-R1模型来自中国公司,无论API服务与开源模型皆受中国政府言论审查,企业与个人使用仍应注意其潜在的内容生成规範与风险,特别是在敏感领域的应用。