原本只在Azure AI Foundry平台开放的Phi-4模型,现在微软在Hugging Face上以宽鬆的MIT授权开源,这代表开发者已经可以自由使用、修改和散布该模型,包括LM Studio等语言模型执行工具已经能够下载并且执行。Phi-4为微软Phi系列的第四代模型,拥有140亿参数,在多项基準测试中展现了与大型模型相匹敌的性能,特别是科学与数学领域。
不同于动辄数百亿甚至数千亿参数的大型语言模型,Phi-4的精简架构使其对运算资源的需求大幅降低。微软表示,Phi-4在1,920个Nvidia H100图形处理器组成的丛集上进行训练,耗时21天完成,其採用了广泛使用的Transformer架构,并进一步精简为仅包含解码器(Decoder-only)的架构,藉此降低模型进行推论时的运算负担。
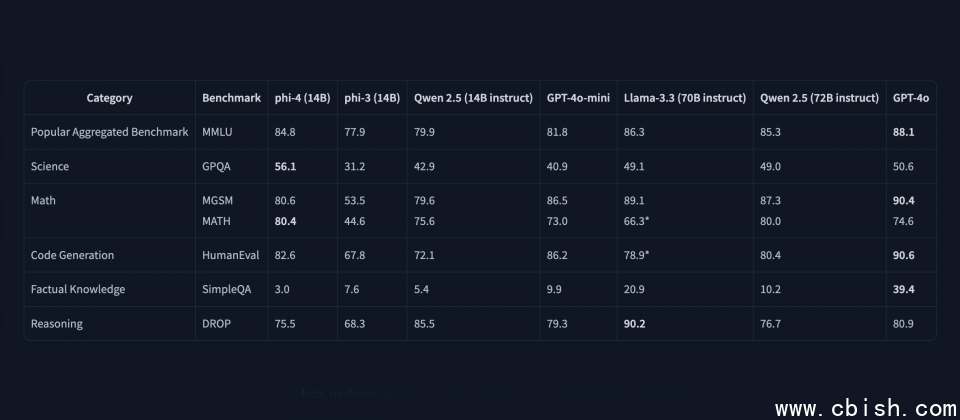
根据微软在Hugging Face上公开的资料,Phi-4在GPQA科学问答及MATH数学题库两项基準测试中,超越了Meta具有700亿参数的Llama 3.3 70B模型,甚至也比GPT-4o表现更好。微软也将Phi-4与其他相近规模的模型进行比较,例如阿里巴巴的Qwen 2.5。Phi-4不仅超越了规模相近140亿参数的Qwen 2.5,甚至与720亿参数的Qwen 2.5版本旗鼓相当。虽然各模型在不同测试中互有领先,但Phi-4展现了小型模型也能达到甚至超越大型模型性能的潜力。
Phi-4仅含解码器的架构影响了其运作模式。相较于标準Transformer模型能分析前后文脉络来理解词彙意义,唯解码器架构模型仅关注当前词彙之前的文本。这种设计虽能降低运算量,但也可能在需要依赖后文资讯才能準确理解的情境下影响其表现。
另一方面,微软透过直接偏好最佳化(DPO)和监督式微调(SFT)等后训练技术,对模型进行了强化,提升模型包括遵循指令的能力、生成内容的品质,以及降低产生有害或不安全输出的风险。
Phi-4的开源使小型语言模型生态更加丰富,近年来,Google的Gemma系列与Meta的Llama 3,以及阿里巴巴的Qwen等模型相继开源,显示各大科技公司皆积极投入小型语言模型的研发。相较于大型模型,小型语言模型在部署成本、能源效率及执行速度都更具优势,特别适合应用于边缘运算、行动装置等资源受限的情境。