Snowflake宣布开源一系列基于SwiftKV技术强化的Llama 3.1模型,这项创新技术能大幅缩短大型语言模型的推论时间,最高可达50%。SwiftKV不仅突破了传统的键值(Key-Value,KV)快取压缩技术,更针对模型推论阶段的计算瓶颈进行全面改进。通过结合模型重组与知识保存自我蒸馏的方法,SwiftKV有效提升吞吐量、降低延迟与运算成本,为企业部署大型语言模型应用提供更高效且经济的解决方案。
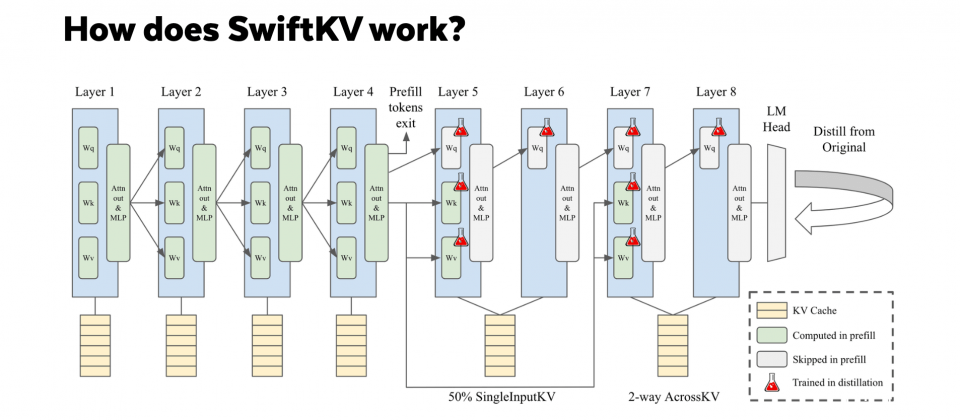
SwiftKV的重点在于改进输入提示的处理过程,研究人员提到,这是企业大型语言模型应用中计算资源消耗的主要来源。在大型语言模型推论过程中,模型会生成大量用于注意力计算的KV快取,这些快取包含关键资讯(Key)和相关资料(Value),帮助模型在输入与输出之间建立关联。Snowflake的研究显示,多数企业工作负载的输入提示长度约为输出生成内容的10倍,而现有的KV快取压缩方法无法有效解决这部分的计算需求。
为此,SwiftKV引入了SingleInputKV技术,利用模型层输出的相对稳定性,允许部分Transformer层跳过计算,直接生成后续所需的KV快取。这一技术不仅大幅降低计算量,还保持了模型的整体準确性,经测试平均仅损失约1%的準确性。
实验结果显示,SwiftKV在Llama 3.1 80亿参数和700亿参数模型上表现出色。对于高负载批次处理使用案例,SwiftKV可将总吞吐量提升至基準模型的2倍,而在即时互动使用案例中,则显着降低了首字元生成延迟(TTFT)与后续生成时间(TPOT)。这种效能提升对需要处理大量长输入的应用场景,如程序码完成、文本摘要和检索增强生成等应用特别适合。
此次开源还包含SwiftKV的推论模型检查点与知识蒸馏工作管线。Snowflake表示,未来将继续改进相关工具,进一步降低大型语言模型的运算成本与资源需求。对于企业来说,SwiftKV可在不牺牲效能的前提下,大幅提升生成式人工智慧应用的经济效益。