
Google本周发布轻量模型Gemini 3.1 Flash-Lite,主打快速、低成本,专为高处理量任务设计。
即日起,Gemini 3.1 Flash-Lite以预览版形式通过Google API在Google AI Studio上线,并通过Vertex AI向企业提供服务。
Gemini 3.1 Flash-Lite以低价和高性能为卖点,号称是Gemini 3系列中速度最快、成本最低的模型。Google引用一项独立基准测试显示,Gemini 3.1 Flash-Lite在Time to First Answer Token(TTFT)上的表现比2.5 Flash快2.5倍,输出速度提升45%。尽管速度更快,其推理与多模态理解能力依然出色:GPQA Diamond得分达86.9%,MMMU Pro达76.8%,均超越2.5 Flash;Arena.ai Leaderboard Elo分数达1432,位居同级别模型榜首。
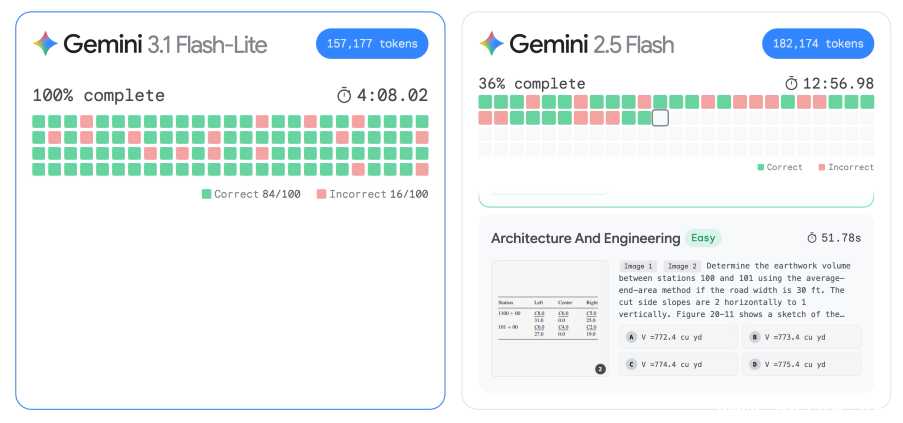
Google表示,3.1 Flash-Lite的高速与强大推理能力,适用于大量开发场景,例如对成本敏感的大规模翻译、内容审核任务,也能胜任需要深度推理的工作,如生成用户界面、仪表盘、构建模拟系统或精准执行指令。
从API价格来看,3.1 Flash-Lite的输入/输出费用为每百万token 0.25/1.5美元,相比2.5 Flash的0.3/2.5美元更为经济。值得注意的是,与同属Lite系列的2.5 Flash-Lite相比,3.1 Flash-Lite定价更高(2.5 Flash-Lite为0.1/0.4美元),但后者输出速度更快。