2025中文大模型巅峰对决:海外领跑,国产开源异军突起
近日,SuperCLUE发布2025年度中文大模型基准测评报告,23个国内外主流模型同台竞技,覆盖数学推理、科学推理、代码生成、语言理解、多轮对话和常识判断六大核心能力。这份被科技圈称为“中文AI年度大考”的榜单,不仅刷新了行业认知,也让国产模型的突围路径愈发清晰。
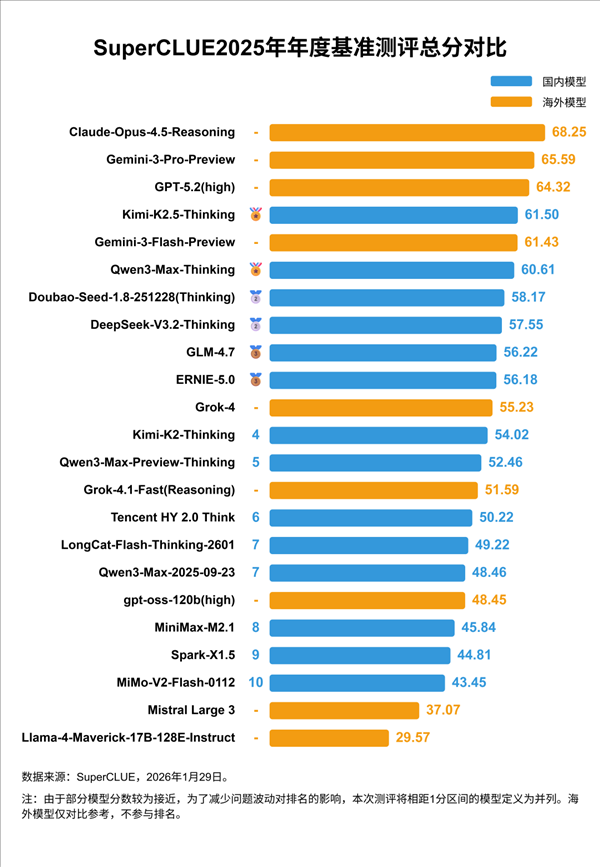
榜单前三名,依然被海外闭源模型牢牢占据。Anthropic的Claude-Opus-4.5-Reasoning以68.25分登顶,其在复杂逻辑链推理和长文本处理上的稳定表现,再次证明了其在高端场景的统治力。谷歌Gemini-3-Pro-Preview以65.59分紧随其后,OpenAI的GPT-5.2(high)则以64.32分位列第三。这三家巨头,依旧掌控着大模型的“技术天花板”。
但真正的惊喜,来自国产阵营——尤其是开源模型。Kimi-K2.5-Thinking以61.50分冲进前四,成为唯一进入Top5的国产开源模型;通义千问Qwen3-Max-Thinking则以60.61分拿下第六,稳居国产闭源第一。更值得关注的是,在细分赛道上,国产模型已经实现“局部反超”。
在代码生成这一高门槛任务中,Kimi-K2.5-Thinking以53.33分力压所有对手,包括GPT-5.2和Gemini-3-Pro,拿下单项冠军。而在数学推理这一传统强项上,Qwen3-Max-Thinking与Gemini-3-Pro-Preview双双达到80.87分,实现并列第一。这不是偶然,而是国产模型在特定场景下,已具备与国际顶尖模型正面交锋的能力。
一个趋势正在显现:闭源模型靠资源堆砌维持领先,而开源模型靠社区迭代和垂直优化实现突破。Kimi和Qwen的崛起,背后是阿里、月之暗面等团队对中文语境的深度理解——比如对古诗文理解、中文逻辑结构、本土常识推理的精准适配,这些恰恰是海外模型难以完全消化的“软实力”。
更值得留意的是,本次测评中,多个国产开源模型在低资源环境下表现优异,甚至在部分任务中优于同等规模的海外闭源模型。这意味着,未来即使没有千亿级算力,中国开发者也能用开源模型做出有竞争力的产品。GitHub上,Kimi-K2.5-Thinking的开源代码已获超12万星标,国内多个AI创业公司正在基于它快速落地行业应用。
从“跟跑”到“并跑”,国产模型正走过最关键的转折点。虽然在整体综合能力上,我们仍与头部有差距,但已经不再只是“能用”,而是“能打”。下一个阶段,谁能率先在教育、政务、医疗等中文刚需场景中做出真正落地的AI产品,谁就可能定义下一代中文AI的生态。
这场竞赛,才刚刚进入白热化。