Essential 发布 RNJ-1:8B 小模型,打出 20B 的拳,背后站着《Attention Is All You Need》的作者
就在昨天,一家名不见经传的团队 Essential,悄无声息地发布了两款开源模型:RNJ-1 Base 和 RNJ-1 Instruct。参数规模只有 8B,却在多个权威基准上直接“越级挑战”20B 级别的开源模型,甚至在部分场景中逼近 GPT-4o 的表现。更让人震惊的是——这家团队的 CEO,正是那篇改变人工智能历史的论文《Attention Is All You Need》的第一作者:阿希什·瓦斯瓦尼(Ashish Vaswani)。
消息一出,Reddit 的 r/MachineLearning 板块瞬间炸锅。版主 bot 主动发帖置顶,热帖点赞破 1.2 万,评论区刷屏:“My god, Vaswani is back.”“这哪是新模型?这是 AI 领域的‘诺曼底登陆’。”
性能炸裂:不是“接近大模型”,是直接跨进大模型区
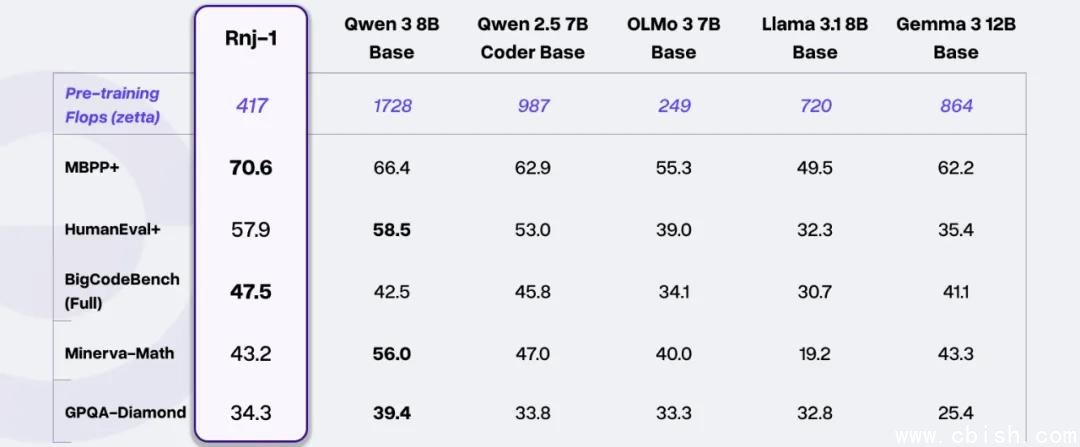
RNJ-1 的成绩单,硬到让人怀疑是不是数据造假:
- 代码生成:在 HumanEval+、MBPP+、BigCodeBench 上全面领先同量级模型,部分任务甚至超越了 20B 的 GPT-OSS 和 Llama 3.1 20B。
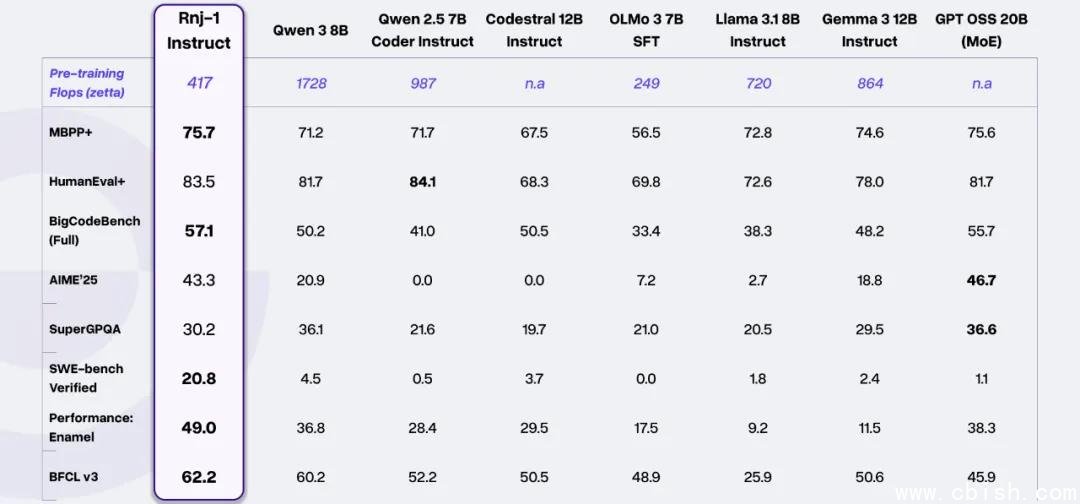
- 软件工程:SWE-bench Verified 得分高达 62.1%,是同级别模型平均分(6.2%)的整整 10 倍。官方称“已进入大模型区间”——这不是营销话术,而是实测:模型能独立阅读 PR、理解上下文、修复多个文件的 bug,甚至能生成可运行的测试用例。
- 数学推理:AIME’25(美国数学邀请赛)得分稳居开源 8B 模型第一;GPQA-Diamond(高难度理科问答)得分 54.7%,仅落后榜首 1.2 个百分点,而榜首是 70B+ 的模型。
- 工具调用:在 Berkeley BFCL 榜单中,Instruct 版本冲进 Top 3,击败了 Mistral 8B、Qwen2.5-7B 等一众竞品,成为目前最强的 8B 工具调用模型。
更离谱的是,这些成绩是在原生 32k 上下文基础上,通过 YaRN 扩展到 128k 仍保持稳定输出的情况下取得的。NVFP4 量化后,推理精度几乎无损,B200 上吞吐量直接翻倍——这意味着,你用一张消费级显卡,就能跑出堪比 70B 模型的推理效率。
技术细节:不靠堆参数,靠“真功夫”
RNJ-1 并非简单照搬 Gemma 3。它的架构融合了多个前沿设计:
- 全局注意力 + YaRN:突破传统滑动窗口限制,实现真正长上下文建模,支持 128k+ 长文档理解,且在多轮对话中不丢失关键信息。
- 执行轨迹训练(Execution Traces):这是 RNJ-1 在代码能力上“封神”的核心。模型不仅看代码,还看代码运行时的每一步变量变化、错误堆栈、调试日志——就像一个资深工程师在盯着 IDE 调试程序。这解释了为什么它在 SWE-bench 上能“自己修 PR”。
- Muon 优化器:取代传统 AdamW,算力利用率提升 30%,训练更稳定,收敛更快,让小团队也能高效训练 8B 模型。
- STEM 语料严格配比:训练数据中 STEM(科学、技术、工程、数学)内容占比超 40%,并经过多轮去重与难度分级,避免“伪知识”污染。
团队甚至在训练中加入了“反向提示”机制:当模型给出错误答案时,系统会自动生成“错误推理链”,让模型学会识别自己的逻辑漏洞——这招,连 Meta 的 Llama 3 都没公开用过。
省钱狂魔:30 人团队,一年省下数百万美元
你很难想象,这支能打出如此战绩的团队,全职成员不到 30 人,没有 Google 或 Meta 的算力资源,却把成本压到极致:
- 混用 TPU v5p 和 AMD MI300X,用 JAX 统一调度,避免框架碎片化。
- 把 Spark 从 GCP 托管服务迁移到 GKE 自建集群,抢占 preemptible 实例,单月节省 $87 万。
- 节点宕机 30 秒内自动恢复,训练任务断点续跑,不浪费一度电。
- 训练数据清洗用自研工具,人工审核成本降低 90%。
CEO 瓦斯瓦尼的原话是:“别内耗,回去练基本功。”他们不追热点,不搞“微调即正义”,而是坚持“先预训练到极致,再谈微调”。项目分两期:先用 200M–2B 小模型验证方向,确认有效后,才敢上 8B 旗舰。
量化之争:Q4 已这么强,Q5/Q6 会有多恐怖?
目前 RNJ-1 只发布了 Q4 量化版本,但社区已经疯狂测试 Q6 版本的潜力。一位独立评测者用私有数据集(涵盖电子电路、啤酒酿造、热力学模拟等冷门领域)对比发现:
- RNJ-1 Q4 在 80% 的任务上超越 Qwen3-4B(2507)——一个曾被奉为“4B 神话”的模型。
- Granite v4 在部分结构化推理任务上反超,但前提是使用 Q6 量化;而 RNJ-1 仍用 Q4,且未做任何专门优化。
“别忘了,这只是 Essential 的第一代模型。”一位资深研究员在评论区写道,“如果他们能把 Q6 做出来,再配上 MoE 架构,2025 年的 8B 模型,可能就是新的基线。”
目前,社区已有人开始尝试将 RNJ-1 Q4 量化为 GGUF 格式,部署在 M4 Max 上本地运行,推理速度稳定在 45 tokens/s,内存占用仅 5.2GB——这意味着,你可以在 MacBook 上跑一个“能自己写代码、解数学题、修 bug”的 AI 助手。
这不是终点,是工具链的起点
当被问及“这是不是大招的前奏?”时,Essential 团队的回应很冷静:
“RNJ-1 只是我们内部工具链的 1.0。我们真正想要的,是让模型能帮我们写框架、自动跑实验、生成论文草稿、甚至改 CI/CD 脚本。等它能独立完成这些,2.0 才是真正的正菜。”
换句话说,他们不是在造一个“能聊天的 AI”,而是在造一个“能当工程师的 AI”。
目前,RNJ-1 已在 Hugging Face 开源,支持 Transformers、vLLM、Ollama 等主流框架。模型权重、训练数据配方、推理脚本全部公开。没有闭源后门,没有商业限制——这在当前 AI 领域,几乎是一种“反常”。
为什么这很重要?
过去三年,AI 的进步似乎被“参数规模”绑架。1B、7B、70B、200B……模型越来越大,训练成本越来越高,普通人越来越难参与。
RNJ-1 的出现,打破了这个幻觉:
- 你不需要 100 亿美元预算,也能做出顶尖模型。
- 你不需要海量标注数据,只要语料够“硬”,就能超越海量清洗的开源数据集。
- 你不需要大厂背书,只要团队有信念、有方法,就能掀翻格局。
阿希什·瓦斯瓦尼,曾用一篇论文开启 Transformer 时代。如今,他带着一支小团队,用 8B 模型,重新定义了“什么是真正的 AI 效率”。
这不只是一个模型的发布。
这是对整个行业的一记耳光。