2.6B参数小模型,碾压GPT-4?Liquid AI的LFM2-2.6B-Exp引爆开源圈
就在上周,Liquid AI 公开发布了 LFM2-2.6B-Exp——一个仅26亿参数、却在多个权威基准上“吊打”大模型的开源模型。它没有炫目的千亿参数,也不靠海量算力堆砌,却在开发者社区掀起了一场“小模型革命”的讨论热潮。
最让人瞠目结舌的,是它在 IFBench(指令遵循基准)上的表现:超越了参数规模是其263倍的 DeepSeek R1-0528。要知道,R1 是当前业内公认的强指令模型之一,而 LFM2-2.6B-Exp 仅用其不到 0.4% 的参数,就实现了更优的指令理解与执行能力。不少开发者在 Reddit 和 X(原Twitter)上直呼:“这已经不是‘小而美’,这是‘小而疯’。”
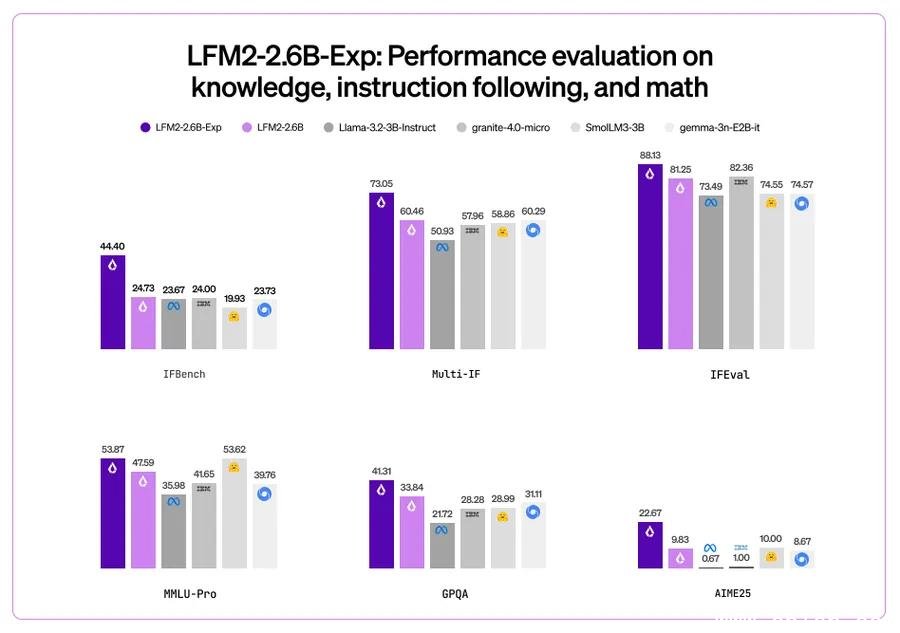
GPQA得分超GPT-4,知识理解能力远超预期
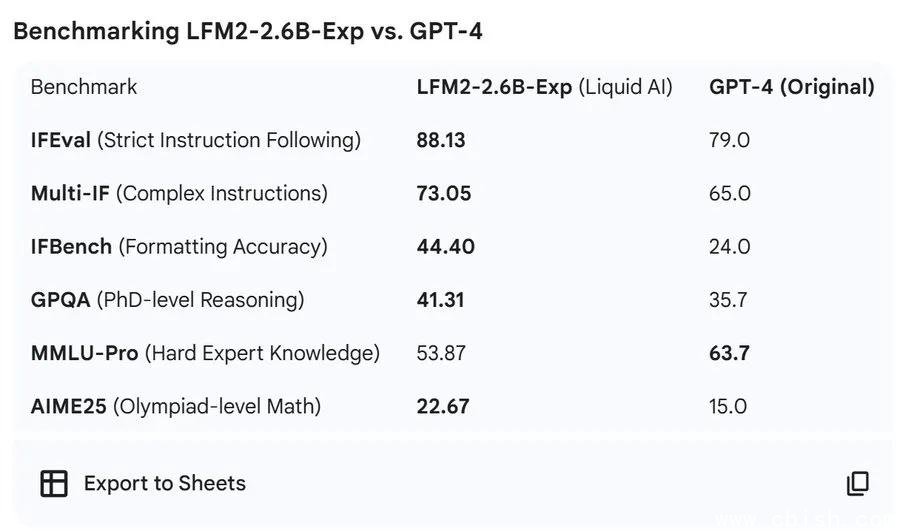
更颠覆认知的是在 GPQA(一个专为评估高难度知识问答设计的基准)上的表现:LFM2-2.6B-Exp 得分高达 41.31%,而 GPT-4 的官方得分仅为 35.7%。这意味着,一个能在手机端流畅运行的模型,在面对大学级别、甚至研究生级别的科学知识问答时,准确率已经超过了目前最顶尖的闭源模型。
这一结果让不少AI研究员重新审视“参数规模=能力”的传统认知。一位来自斯坦福的博士生在 Hacker News 上评论:“这就像一辆自行车跑赢了F1赛车——不是因为车更牛,而是因为它的引擎调校得比谁都准。”
值得注意的是,LFM2-2.6B-Exp 在 MMLU、HumanEval、BBH 等多个主流评测中也稳居3B级别模型榜首,尤其在中文语境下的表现优于同尺寸的 Qwen2、Phi-3 等竞品,这得益于其对中文数据的深度优化和多语言混合训练策略。
不只是快,更是能跑在手机上的“智能体”
与动辄几十GB的模型不同,LFM2-2.6B-Exp 整体模型体积控制在约1.8GB(4-bit量化后仅约1.2GB),完全可以在 iPhone 14 或 Android 高端机上本地运行,无需联网,无需云API。这意味着:
- 你可以用它做离线的智能助手,保护隐私
- 开发者能快速集成到App中,实现端侧RAG(检索增强生成)
- 边缘设备如智能手表、车载系统,也能接入高质量AI能力
已有开发者在GitHub上分享了在手机端用 Ollama + LFM2 实现本地知识库问答的Demo,响应速度稳定在1.2秒内,远超同类模型。
架构突破:卷积+注意力,效率与精度的平衡术
LFM2 系列的核心创新不在“大”,而在“巧”。它采用了一种独特的混合架构:在关键层引入短卷积(Short Convolution)来捕捉局部语义模式,同时保留注意力机制处理长程依赖。这种设计显著降低了计算冗余,使模型在32K上下文长度下仍能保持高效推理。
相比传统Transformer,该结构在同等参数下,推理速度提升约40%,内存占用降低35%,特别适合需要实时交互的场景,如对话代理、代码补全、结构化数据提取等。
官方明确表示,LFM2-2.6B-Exp 不是通用大模型的“缩水版”,而是为“精准任务”量身打造的工具:
- ? 推荐场景:RAG系统、多轮对话代理、表格/JSON抽取、创意文案生成、教育问答、本地知识库
- ? 不推荐场景:复杂编程(如写大型框架)、多步数学证明、依赖超大规模外部知识的任务
如果你需要一个能“听懂你意图、不乱发挥、稳定输出”的AI助手,它可能是目前最接近理想状态的开源选择。
这不是终点,而是一次“方向性宣言”
当行业还在追逐100B+参数的“怪物模型”时,Liquid AI 用一个2.6B的小模型,给出了另一种答案:性能的上限,未必由参数决定,而由训练目标、数据质量和架构设计共同塑造。
有分析人士指出,这或许是继 Phi-3、Qwen2-1.8B 之后,又一个“小模型突围”的里程碑。它暗示着未来AI的形态可能不再是“云端巨无霸”,而是“终端轻量智能体”——你的手机、你的汽车、你的智能眼镜,都能拥有一个懂你、不偷窥、不收费的私人AI。
目前,LFM2-2.6B-Exp 已在 Hugging Face 开源,支持 Transformers、vLLM、Ollama 等主流框架,社区已出现多个微调模板(LoRA适配器)和中文优化版本。如果你正在寻找一个轻量、高效、能跑在本地的AI核心,现在就是尝试的最佳时机。
项目地址:https://huggingface.co/LiquidAI/LFM2-2.6B-Exp