英伟达悄然发布Nemotron 3 Nano 30B-A3B:开源、轻量、炸裂性能
没有发布会,没有直播,没有KOL造势——英伟达只是在Hugging Face上挂出一篇技术报告,标题平淡得像一份内部笔记:《Nemotron 3 Nano 30B-A3B: A Sparse, Efficient, Long-Context Foundation Model》。可当你点开它,才发现这是一次对行业规则的无声颠覆。
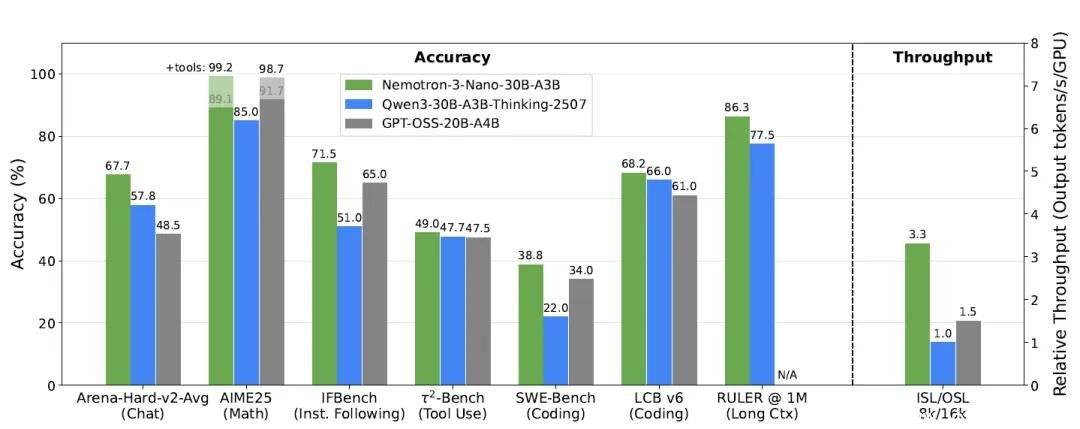
这款模型总参数31.6B,但每次推理仅激活3.2B(含嵌入层3.6B),真正实现“按需唤醒”。这不是噱头,是实打实的架构革命。在8K输入+16K输出的典型长文本场景下,它的推理速度达到Qwen3-30B-A3B的3.3倍、GPT-OSS-20B的2.2倍。一张消费级H200显卡就能流畅运行,连笔记本电脑上的RTX 4090都能跑出接近80%的性能——这在以往,是百亿参数模型才敢想的事。
100万token上下文,不是PPT,是真能用
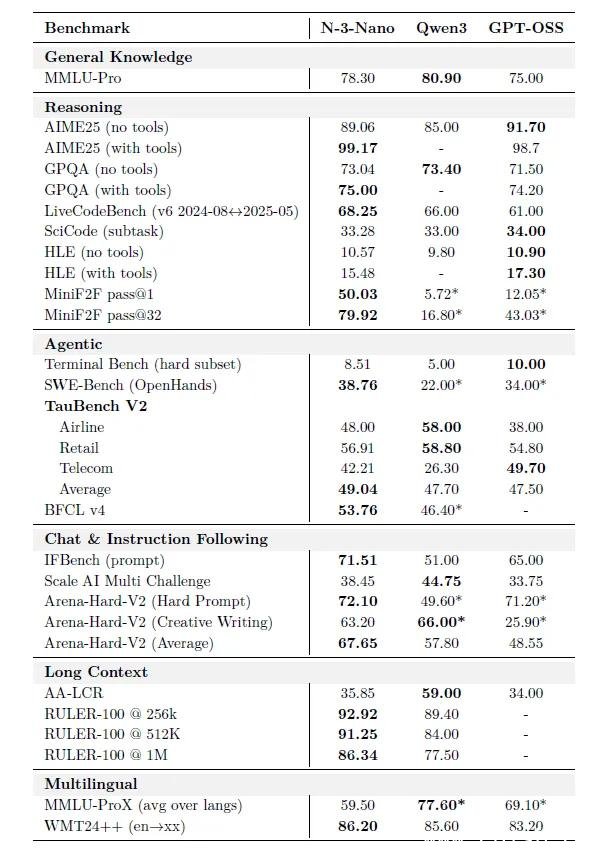
长上下文不再是“能跑就行”的演示功能。Nemotron 3 Nano通过连续预训练+256k合成检索数据,将上下文窗口直接拉到100万token——是主流模型的5倍以上。在权威基准RULER 1M上,它拿下86.3分,领先第二名近10分。
这意味着什么?
- 整本《战争与和平》+注释+批注,一次性喂进去,它能精准定位某段对话的上下文关系;
- 一个500页的PDF技术手册,它能自动提取关键参数、交叉引用公式、生成摘要;
- 一个包含300个文件的GitHub仓库,它能读懂项目结构、识别bug模式、甚至建议修复方案。
这不是“记忆变长”,而是真正理解了“信息之间的关系”。开发者已经开始用它做法律合同比对、科研论文综述、企业知识库问答——这些场景,过去靠人工读三天,现在AI十分钟搞定。
数学、代码、工具调用,三线齐发,全栈通吃
很多人以为“小模型”只能做简单任务。Nemotron 3 Nano用数据打脸。
数学能力:在AIME 2025竞赛题(美国高中数学顶级赛事)中,无工具模式下得分89.1,启用Python解释器后直接飙到99.2——只差0.8分就是满分。这比GPT-4o和Claude 3.5 Sonnet的开源版本还高。
代码实战:LiveCodeBench得分68.3,超过Qwen3-30B的66.1,领先GPT-OSS-20B整整7分。它不仅能写Python,还能理解C++模板元编程、调试Rust生命周期错误、甚至根据注释自动生成单元测试。
软件工程:SWE-Bench得分38.8,开源模型第一。它能直接读取GitHub Issue,定位源码位置,生成修复PR,连提交信息都写得符合社区规范。有开发者实测:它修复了自己项目里一个困扰两周的Docker权限问题。
工具调用:BFCL v4得分53.8,在航空、零售、电信三大真实业务场景中平均达49分。你能让它:
- “帮我查下下周一从洛杉矶飞纽约,下午3点前落地,价格最低的航班,带行李”
- “对比我过去三个月的电费账单,找出异常波动时段,并生成节省建议”
- “我被电信公司多收了500块,帮我起草一封正式投诉信,附上合同条款编号”
它不是“能调工具”,是“懂怎么用工具解决问题”。
FP8量化不掉精度?这波是真降本
大多数模型一量化就崩,Nemotron 3 Nano反其道而行:它把18层中的12层(非关键注意力与Mamba层)全压成FP8,仅保留6层注意力+6层Mamba用FP16,精度损失不到1%。
结果?吞吐量提升30%,显存占用下降40%。在Jetson AGX Orin这类边缘设备上,它能以15 token/s的速度持续运行——这意味着你在无人机、工业机器人、车载系统里,也能部署一个“懂长文、会写代码、能订机票”的AI大脑。
更狠的是,英伟达公开了完整的量化配置文件和校准数据集,开发者可一键复现,无需重新训练。
25T token训练数据,全开源,连“怎么教它”都给你
预训练阶段,团队用了25T token,其中:
- 2.5T全新英文网页(2023–2025年爬取,避开常见数据污染)
- 428B代码(含Python、C++、Rust、Julia、SQL,覆盖GitHub热门项目)
- 31.7B STEM推理问答(来自竞赛题、教科书、科研论文)
全部开放在Hugging Face,连数据清洗脚本、去重规则、版权过滤逻辑都一并放出。更夸张的是,他们还公开了:
- 代码转译数据集:Python → C++、Java → Go 的自动转换样本
- 跨学科合成题:比如“用微积分推导量子隧穿概率,再用Python模拟”
- 数学题生成器:自动生成符合AIME/IMO难度的原创题
这不是“给点数据”,这是把“如何训练下一代AI”的完整路线图交到你手上。
三步后训练:让AI听懂人话,而不是背答案
模型再强,不会“对话”也是摆设。Nemotron 3 Nano的后训练三板斧,堪称教科书级别:
1. 监督微调(SFT):1800万条高质量对话,涵盖竞赛解题、终端命令、工具调用流程。它学会了“什么时候该用工具”“什么时候该停顿思考”“预算超了怎么办”。
2. 多环境强化学习(RLVR):同时训练数学、代码、长文QA、指令遵循等10个任务,避免“偏科”。训练200步后,全面反超SFT效果,模型不再“死记硬背”,而是学会策略性思考。
3. 人类反馈强化(RLHF):英伟达自研生成式奖励模型GenRM,采用16选1环形对比机制,加入“长度惩罚+简洁奖励”——结果?回答平均缩短30%,但信息密度不降反升。用户反馈:“它现在不像机器人,像一个聪明的实习生,话不多,但句句到点。”
开发者能做什么?成本直降70%,部署门槛崩塌
过去,跑一个30B模型需要A100×4,成本超$1000/小时。现在,一张H200或RTX 4090就能跑,推理成本下降70%以上。这意味着:
- 中小团队可以自建企业知识库,不用再买GPT-4 API;
- 教育机构能部署本地AI助教,学生可随时提问数学、编程、论文问题;
- 开发者可以把它嵌入桌面应用、浏览器插件、甚至手机App,实现“离线智能”。
已经有团队用它做:
- 法律AI助手:自动分析合同条款,标记风险点
- 科研协作者:读完50篇论文,自动生成文献综述表格
- 客服机器人:处理复杂退费纠纷,准确率超人工
项目地址:开源,免费,可商用
你不需要申请,不需要等待,直接访问:
https://huggingface.co/papers/2512.20848
模型权重、训练代码、数据集、评估脚本、量化配置——全部开放。英伟达这次,不是在发布一个模型,而是在点燃一场“轻量AI革命”的火种。
接下来,看你的了。