Anthropic于周一(11月24日)正式发布最新模型Claude Opus 4.5,带来长上下文处理、计算机操作能力、全新effort参数与“无限聊天”等重大升级,同时将价格下调至每百万token输入5美元、输出25美元,仅为前一代Opus 4.1的三分之一。
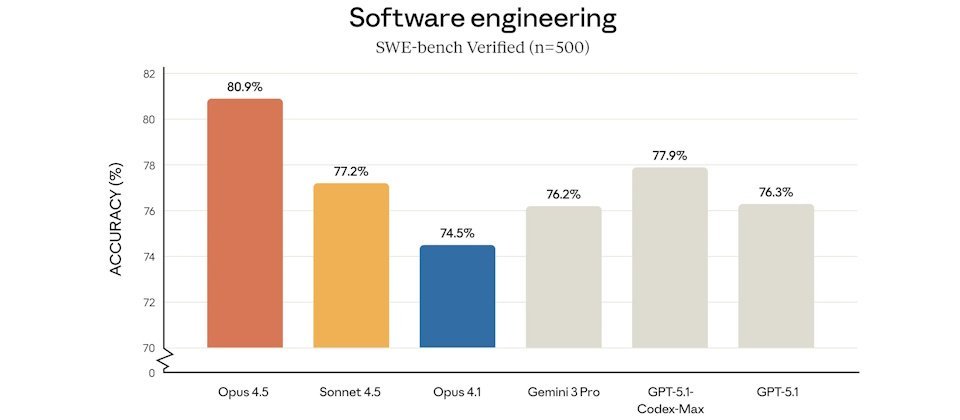
Opus 4.5在多项基准测试中达到业界顶尖水平,包括评估真实代码修复能力的SWE-Bench、测试终端操作与编程环境任务的Terminal-bench、检验代理工具调用效率的tau2-bench,以及评估高难度推理与知识深度的GPQA Diamond。其中最受关注的是,它成为首个在SWE-Bench Verified中突破80%的模型,显示出其代码修正能力已接近甚至超越专业水平。
另一个标志性里程碑是,Opus 4.5首次在Anthropic的技术工程测试中胜过所有人类考生。这份可带回家完成的测试专为性能工程岗位应聘者设计,要求在两小时内完成高难度题目,以评估技术能力与判断力。Opus 4.5通过并行推理聚合方式,在限时测试中取得历史最高分;若不设时间限制并在Claude Code中使用,模型表现则与公司过往最佳人类候选人相当。
Opus 4.5还引入了新的effort参数,允许开发者在推理深度、速度与成本之间调整计算强度。在中等effort模式下,Opus仅需远低于Sonnet 4.5的token用量即可达到相同最佳成绩,节省76%的token;在最高effort模式下,性能进一步提升的同时仍保留近五成的token节省空间,有助于企业根据任务需求选择最高效的计算策略。
为展示Opus在计算机操作方面的能力,Anthropic同步推出可配合使用的Chrome和Excel集成工具。Opus 4.5具备新的Screen Zoom Tool,可主动要求放大屏幕区域以检查按钮、字段或UI细节,并能在跨标签页、跨窗口及大型文档间实现更精准的操作。Chrome扩展程序将此能力延伸至浏览器工作流,而Excel集成则让模型能够协助生成数据透视表、图表与跨表格处理,展现其在实际计算机任务中的应用能力。
在长上下文处理方面,Opus 4.5重新调整了模型的记忆管理策略,引入“选择性上下文压缩”机制,能在上下文接近上限时自动提取并保留关键内容,不会中断对话或导致上下文错乱,也无需用户手动摘要。这一改进带来了“无限聊天”功能,使跨天、跨文件、多轮次的长期项目能够持续进行,不受上下文长度限制。
尽管Opus 4.5的价格大幅下调三分之二,但相较竞争对手仍属较高水平。例如,OpenAI的GPT-5.1每百万token输入费用为1.25美元、输出为10美元;Google的Gemini 3 Pro则为输入2美元、输出12美元。