为什么AI需要一场搜索革命?
当你在浏览器里输入“如何治疗轻度抑郁症”,搜索引擎会给你一长串网页链接——新闻、论坛、百科、广告,全都要点开才能找答案。但AI不是人。它不会点击,不会滑屏,更不会耐心读完5000字的长文。它要的是:精准、浓缩、可直接推理的信息块。
传统搜索为人类设计,Parallel Search 却是为AI重建的引擎。它不排名URL,它排名“信息密度”。一句话、一段数据、一个公式——只要能直接支撑AI做决策,它就值得被优先提取。
不再“找网页”,而是“挖知识”
Parallel Search 彻底抛弃了关键词匹配的老路。它不看你页面里有没有“抑郁症”“治疗”“SSRI”这些词,而是理解你真正想问的是:“有哪些循证有效的非药物干预方法,适合轻度患者,且副作用最小?”
它像一个经验丰富的研究员,扫过数百万网页,自动过滤掉营销话术、重复内容和低质问答,只留下经过验证的医学指南、临床研究摘要、权威机构建议——并把它们压缩成AI能直接吞下的语义单元。
这不是“搜索结果”,这是“知识切片”。
一次调用,抵得上十次传统搜索
在多跳推理任务中——比如“对比苹果和华为2024年AI手机的电池续航实测数据,并分析其对用户日常使用的影响”——传统API需要AI先搜“苹果iPhone 15电池续航”,再搜“华为Mate 60电池测试”,再找“用户使用行为分析报告”,三次调用,耗时超3秒,Token消耗超2000。
Parallel Search 一次请求,直接输出:
- iPhone 15 Pro:平均续航8.2小时(TechRadar实测,2024.10)
- 华为Mate 60 Pro:平均续航9.1小时(ZEALER实验室,2024.9)
- 用户调研:续航>8.5小时可减少日均充电次数37%(Counterpoint 2024 Q3)
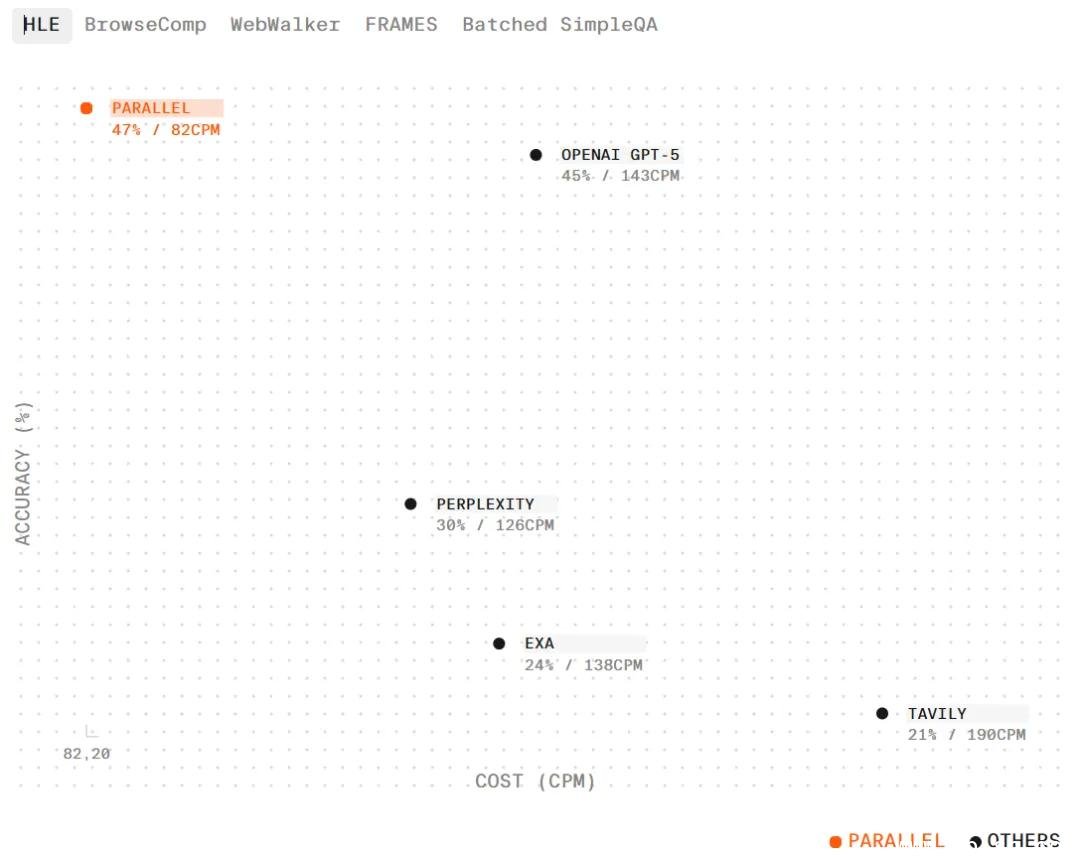
准确率提升92%,成本降低48%,响应时间缩短至0.7秒。
真实场景验证:自家AI代理每天跑500万次
Parallel Search 不是实验室里的概念产品。它驱动着Parallel自家的Web Agent——一个每天处理超过500万次真实用户请求的自动化系统,从比价、订票、合同分析到舆情监控,全靠它提供信息。
每一次优化,都来自真实世界的反馈:用户说“你上次给的财报数据过时了”,系统立刻调整抓取优先级;用户问“为什么这个推荐和我三天前的查询矛盾?”,系统自动加入时间戳与来源可信度权重。
这不是“拟人化搜索”,这是“工程化知识提取”。
不只是更快,是更省、更准、更聪明
在SimpleQA这类简单问答测试中,Parallel 的准确率与Google Search API、Perplexity等顶尖系统持平,但平均Token消耗低35%,成本低47%——这意味着,如果你是开发者,用它做AI客服、知识库、智能助手,每月API费用能省下数千美元。
更重要的是,它支持“上下文继承”:AI在上一轮对话中提取的结构化信息,可直接作为下一轮查询的输入,无需重复检索。这在多轮交互场景中,是颠覆性的效率提升。
未来已来:AI不再“阅读”网页,而是“消费”知识
我们正从“搜索时代”进入“知识即服务”时代。AI不需要网页,它需要的是:可验证的、结构化的、可执行的信息。
Parallel Search 的目标很清晰:让AI在100毫秒内,获得过去需要人类花10分钟才能整理出来的核心知识。
它不是在优化搜索,它是在重新定义“信息获取”本身。