豆包语音识别 2.0 正式发布:能听懂语境、看懂图像的下一代语音引擎
12 月 5 日,火山引擎正式推出豆包语音识别模型 2.0——这不是一次简单的参数优化,而是一场从“听字”到“懂意”的技术跃迁。新版本首次将上下文理解、多模态感知与跨语言支持深度融合,让语音识别不再只是机械转写,而是真正具备“人一样”的语义推理能力。
过去,语音系统依赖词库和历史记录来判断发音,遇到“筠州”“鄞州”“云州”这类生僻地名,或“重”“行”“乐”等多音字,极易误判。而豆包语音识别 2.0 通过实时语境建模,能动态分析对话主题。比如当用户在讨论苏轼家族时说出“筠州”,系统会自动关联“苏辙曾被贬至筠州”的历史背景,精准识别出地理名词,而非误听成“军州”或“均州”——这种能力,已接近人类听者的常识推理水平。

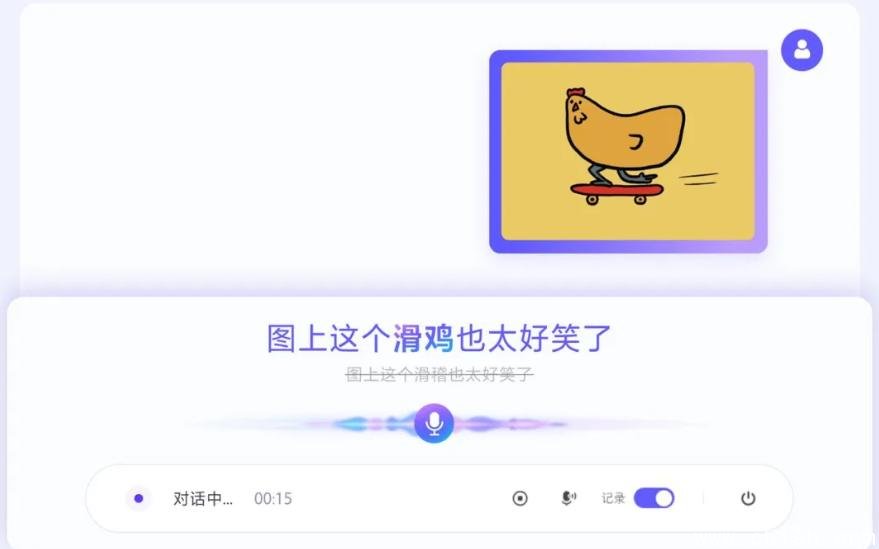
看图说话:语音+图像双模态,彻底告别“滑鸡”变“滑稽”
你有没有过这样的经历:对着手机照片说“把这只滑鸡的翅膀修一下”,结果系统转成“把这只滑稽的翅膀修一下”?在电商、内容创作、智能客服等场景中,这种误识不仅影响效率,更可能引发严重沟通误差。
豆包语音识别 2.0 率先实现语音与视觉的深度协同。当用户在“搜拍”或“AI修图”中边看图边语音指令时,系统会同步分析图像中的主体、动作、颜色与结构。例如,若图像中是一只穿着滑板鞋、正在滑板的鸡,哪怕用户口音模糊或语速偏快,系统也能锁定“滑鸡”为正确词,而非“滑稽”“华机”等同音干扰项。
在设计场景中,用户说“把马头改小一点”,系统不再仅靠语音猜测,而是结合画面中马匹的轮廓、位置和比例,精准识别“马头”这一视觉实体,避免误判为“码头”“马头山”等无关词汇。这一能力已实测在电商详情页修改、短视频字幕生成、AI绘画指令输入等场景中,准确率提升达 35% 以上。
13 种语言全覆盖,跨境直播、海外客服一键接入
在保持对普通话、粤语、四川话、东北话等方言高精度识别的基础上,豆包语音识别 2.0 进一步拓展多语种支持,目前已全面覆盖日语、韩语、德语、法语、西班牙语、印尼语、葡萄牙语、意大利语、俄语、泰语、越南语、阿拉伯语和英语,共计 13 种主流语言。
这意味着: - 跨境电商主播无需再为外语字幕发愁,直播实时字幕准确率超 92%; - 海外客服系统可直接处理多语种来电,自动转写并分类工单; - 海外用户用母语描述商品需求,中文运营团队也能精准理解; - 多语言会议记录、跨国培训内容,一键生成高质量文字稿。
据火山引擎内部测试,该版本在非母语口音、背景噪音、快速连读等复杂场景下,WER(词错误率)较上一代降低 28%,达到行业领先水平。
已上线企业API,开发者可免费接入体验
目前,豆包语音识别 2.0 已在「火山方舟体验中心」开放试用,企业用户可通过 API 快速集成至客服系统、智能硬件、音视频平台、车载系统等场景。首批接入客户包括多家头部直播平台、AI绘画工具厂商和跨境电商服务商,反馈显示“误识率下降明显,人工校对成本降低近四成”。
官方透露,下一步将重点推进“语音+文本+手势”三模态融合,未来或将支持通过语音+手势方向,精准控制画面元素缩放、移动等操作,真正实现“动口不动手”的智能交互体验。
无论是内容创作者、企业服务提供商,还是智能硬件开发者,豆包语音识别 2.0 都在重新定义“语音输入”的边界——它不再只是把声音变成文字,而是让你的声音,真正成为与数字世界对话的语言。