Google发布开源嵌入模型EmbeddingGemma,定位在设备端离线场景下,提供语义搜索与检索增强生成(RAG)所需的文字向量。官方指出,该模型以3.08亿(308M)参数在MTEB多语榜单中,是5亿(500M)参数以下的开源模型中排名最高,支持100多种语言,并通过量化感知训练降低内存占用,可在低于200 MB内存环境中运行,目标是让移动设备、笔记本与台式机在无网络下也能完成检索与问答。
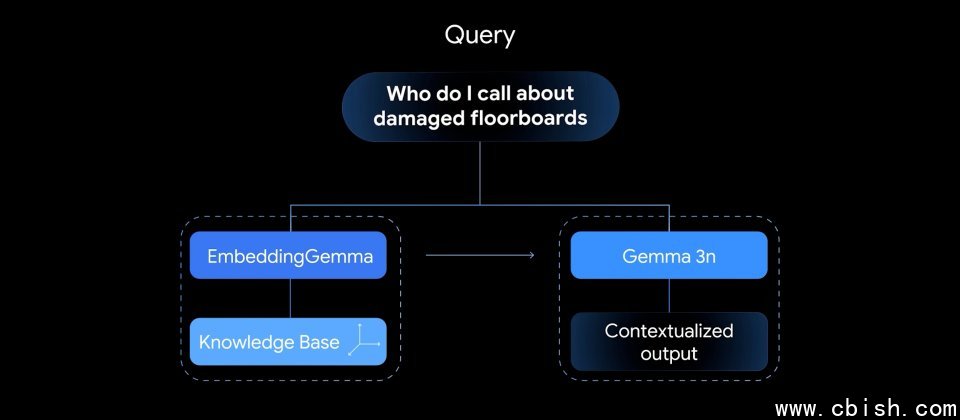
EmbeddingGemma以Gemma 3架构为基础,由约1亿(100M)模型参数与约2亿(200M)嵌入参数组成。模型提供约2,000 Token上下文长度,并与Gemma 3n共用分词器,便于在同一设备上通过EmbeddingGemma完成检索,再交由Gemma 3或Gemma 3n生成回答,减少系统整体内存使用量。官方强调在EdgeTPU上处理256 Token输入时,嵌入推理延迟可低于15 ms,对实时互动式应用具有参考价值。
EmbeddingGemma采用Matryoshka Representation Learning(MRL),单一模型即可输出多种维度的向量,提供768、512、256与128等尺寸选择,让开发者在检索质量、延迟与存储成本之间进行权衡调整。对RAG流程而言,检索阶段的相似度计算依赖嵌入质量,嵌入越能刻画语义与语境,越有助于找出与查询最相关的段落并减少离题或错误回答。
EmbeddingGemma以离线与隐私为设计重点,文档与查询的向量化都在本地硬件完成,可用于搜索个人文件、短信、电子邮件与通知等数据来源,或构建企业知识库本地检索入口。模型与常见工具链整合,包括llama.cpp、MLX、Ollama、transformers.js、LM Studio、LlamaIndex与LangChain,并提供浏览器端的互动演示以可视化文字嵌入。
Google将EmbeddingGemma定位为设备端的嵌入解决方案,对于需要离线运行、注重数据主权或希望在终端快速响应的应用较为合适,而面向大规模服务器端服务,官方建议改用Gemini Embedding。