GitHub发布新的Copilot嵌入向量模型
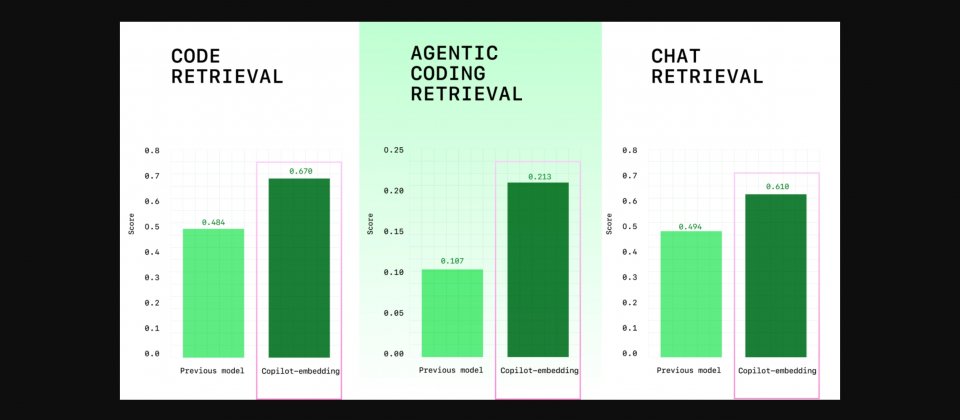
GitHub发布新的Copilot嵌入向量模型,主打在VS Code中更精准即时地找出与开发者意图相符的代码片段,同时降低本地与服务器端的内存负担。官方测试显示,检索质量提升37.6%,嵌入(Embedding)吞吐量提升约2倍,索引内存占用约为原来的八分之一,预期可让Copilot聊天与代理响应更准确,结果返回更快,并减少在大型项目上的资源消耗。
此次模型已用于Copilot的情境提取,涵盖聊天、代理、编辑与询问模式。开发者在寻找函数、测试、跨多个文件的工具函数,或追踪错误字符串的处理位置时,将更容易找到问题核心的代码,而非语义相近却无法直接使用的片段。GitHub并指出,在VS Code中的建议代码接受率也明显上升,C#开发者提升110.7%,Java开发者上升113.1%。
GitHub表示,新模型的设计重点是让开发者在实际工作中能更快更准确地找到需要的代码,同时控制响应时间与内存使用量。团队在训练过程中采用一种比较不同代码片段的方法,让模型学会分辨看起来相似但意义不同的内容,并能根据不同情境使用多种规模的运算方式,以兼顾速度与资源效率。
为了避免搜索时出现看似正确实际错误的结果,新模型特别加入了大量具有挑战性的训练数据,这些示例虽然与问题非常接近,但答案并不正确。这些数据来自公开的GitHub代码库,以及微软与GitHub的内部项目,再通过大型语言模型协助挑选出最容易混淆的案例。
语言分布方面,数据集前5名分别为Python约36.7%、Java约19.0%、C++约13.8%、JavaScript或TypeScript约8.9%、C#约4.6%,其余语言合计约17.0%。在评测上,GitHub采用多重基准而非单一测试,涵盖从自然语言到代码、代码到自然语言、相似功能搜索,与问题到代码(Problems to Code)的修正建议等不同方面,目标是在多样化情境中维持稳定质量。
对用户最直接的改变是VS Code端搜索响应更敏捷,且在大型代码库中建立与保存索引的成本下降,对本地内存较敏感或需要同时打开多个工作区的开发者尤其明显。服务器端因索引缩小也更容易扩展规模,对团队与企业级场景能提供较稳定的响应时间,进一步改善Copilot在聊天、代理与编辑建议中的整体表现。
GitHub表示,未来将持续扩充支持的编程语言与代码仓库,并持续改进困难负例(Hard Negative)数据的筛选流程,让模型能更精确地识别代码间的细微差异。随着运算效率的提升,团队也计划把多余的性能资源投入到训练更大、精度更高的模型上。