 图片来源:
图片来源: Google DeepMind
Google DeepMind周三(7/23)发表了可用于分析罗马时代拉丁铭文的AI模型Aeneas,并透过Predicting the Past网站开放使用;该网站同时也整合了先前推出、用于分析古希腊铭文的模型Ithaca。
在西元前6世纪至西元5世纪的古罗马时代,人们通常将文字(拉丁文)写在羊皮纸、莎草纸、蜡板、石头或金属上。其中,只有刻在石头与金属上的铭文较易保存至今。为了协助历史学家更有效地解读、归属并修复这些残缺的文本,Google DeepMind开发出Aeneas——号称是首个具备「古代铭文脉络化」能力的AI模型
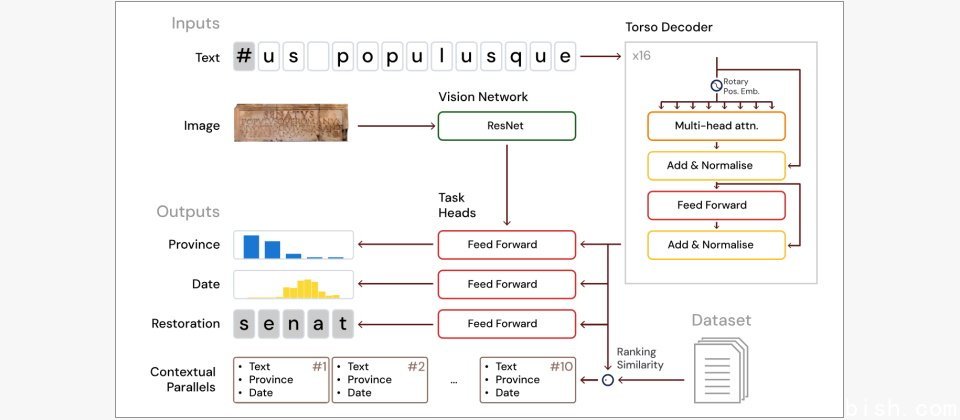
Aeneas是一个多模态生成神经网路,支援文本与图像输入。Google DeepMind团队首先策画了一套资料集,整合了罗马铭文资料库(Epigraphic Database Roma,EDR)、海德堡铭文资料库(Epigraphic Database Heidelberg,EDH),以及Clauss-Slaby铭文资料库(Epigraphic Database Clauss Slaby,EDCS-ELT)。团队将这些经过清理与统整的纪录,彙编为一个可供机器操作的资料集,名为拉丁铭文资料集(Latin Epigraphic Dataset,LED),内容涵盖来自古罗马世界的17.6万则拉丁文铭文。
Aeneas模型会先读取铭文的文字,并利用Transformer技术分析内容;如果铭文有缺字,模型会尝试补上;若不清楚是哪一年写的,也会预测其年代;而在判断铭文的地理来源时,则会同时参考铭文的照片。接着,Aeneas会使用嵌入(embedding)技术,将铭文的内容与背景资讯转换成一组数值,形成其独特的「历史指纹」,并据此从拉丁铭文资料集(LED)中找出最相似的铭文,依相似度排序后,提供学者作为参考依据。
Google DeepMind团队表示,Aeneas不仅能修复最多10个字元的缺文,其Top-20準确率高达73%,即使缺文长度未知,準确率也仍有58%。使用者除了可透过网页版与之互动外,也已透过GitHub同步释出原始码及资料集。