 图片来源:
图片来源: Meta
Meta本周公开了Llama模型安全工具,以防範Llama模型越狱、提示注入攻击,此外也发表SOC AI安全评估工具、以及供企业防止资料外洩、与deepfake诈骗的检测工具。
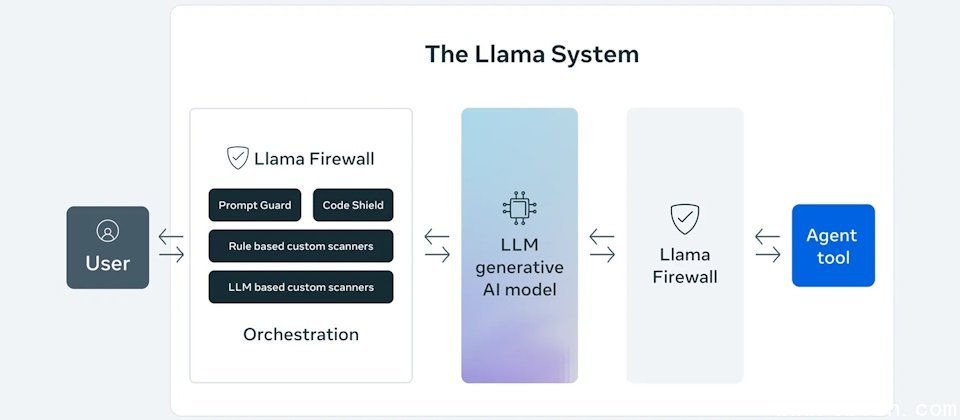
最新的LlamaFirewall是LLM护栏工具,它作用于使用者和LLM模型、以及模型与代理人之间,可与Meta的防护模型像是Llama Guard、Prompt Guard,以及和CodeShield过滤工具、扫瞄工具协同,以侦测并防止提示注入、不安全程序码,或是和可疑的LLM外挂互动。
Llama Guard 4为可客製化Llama Guard模型的最新版,为120亿参数的多模态安全模型,能理解多模态包括文字和图片输入。Guard 4并提供多个模型检查点及互动式notebook方便用户微调。
Meta并提供2个Prompt Guard 2指令安全模型。Prompt Guard 2 86M为Prompt Guard分类器模型的最新版,提高了越狱及指示注入的侦测能力。Prompt Guard 2 22M则为轻巧版,声称较86M版降低75%延迟性及运算需求。如同Prompt Guard,新模型都可支援非英语的提示输入检查。
上述安全工具已于Llama Protections网站、Hugging Face及GitHub向社群公开。
除了Llama护栏工具,Meta也发表开源安全评估套件CyberSec Eval 4二项工具。一为Meta和CrowdStrike合作开发,以量测安全监控中心(SOC)AI效能的CyberSOC Eval框架,本工具很快会公开。第二则是AutoPatchBench,用以评估Llama和其他AI系统自动修补安全漏洞的能力。
Meta另外透过Llama Defender方案,将二项安全工具分享给特定合作伙伴。一为Automated Sensitive Doc Classification Tool,可分类、标籤内部重要文件,防止员工无授权存取或散布,目前已可在GitHub下载。二是Llama Generated Audio Detector & Llama Audio Watermark Detector,可侦测文件或照片是否为AI生成,防止诈骗或钓鱼,本工具已提供给ZenDesk、Bell Canada及AT&T整合于其系统中。其他企业也可申请加入。
最后,Meta为WhatsApp也展示了名为Private Processing的工具。该工具和Meta AI一样能协助摘录未读讯息、或是润饰信件,但它能确保隐私,连Meta或WhatsApp都无法存取。不过该工具目前仍由Meta和安全专家合作改善中,日后才会正式推出。