Google Gemma 3模型正式支援QAT(Quantization-Aware Training)技术,同步释出多种已量化版本,让开发者即便使用消费级显示卡如Nvidia RTX 3090,也能在本地执行最多达270亿参数的语言模型,进一步降低大型人工智慧模型的硬件门槛,扩大本地部署与边缘运算应用可能性。
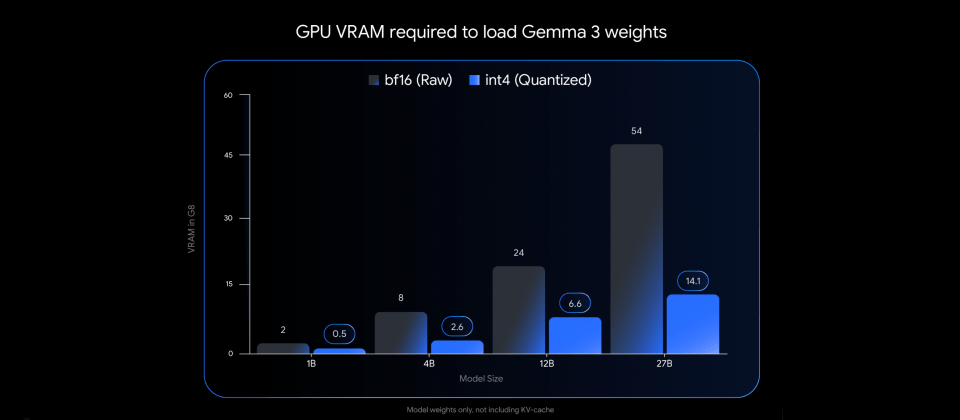
Gemma 3原始模型以BF16格式于Nvidia H100等高阶GPU上执行,可提供先进的推论效能。而本次QAT版本则是透过训练期间模拟低精度运算,有效抑制传统量化技术可能带来的效能衰退,支援int4格式,大幅缩减模型权重所需GPU记忆体容量。Gemma 3 27B模型经QAT后,以int4格式储存时仅需约14.1 GB VRAM,较原本BF16格式的54 GB显着降低,实际已可在RTX 3090等显示卡载入执行。
新版本整合主流开源工具与本地推论框架,开发者可透过Ollama、LM Studio、MLX、llama.cpp与gemma.cpp等平台快速载入,并开始使用QAT版本模型。官方模型目前已于Hugging Face与Kaggle开放下载,支援常见的GGUF格式与Q4_0变体,也可搭配社群贡献的PTQ模型版本使用。