法国新创公司Mistral AI宣布推出最新的人工智慧模型Mistral Small 3.1,根据官方公布的基準测试资料,Mistral Small 3.1的整体效能表现,尤其在视觉理解及长上下文处理方面,明显优于Google日前释出的Gemma 3同级模型。
Mistral Small 3.1主打适合本地端部署,与Gemma 3 27B皆属于中型规模百亿级参数的多模态人工智慧模型,具备轻量化的特性,能够在一台搭载单张Nvidia RTX4090显示卡的装置,或是32 GB记忆体的Mac电脑上运行,但Mistral Small 3.1各项技术效能指标,则已经领先Gemma 3。
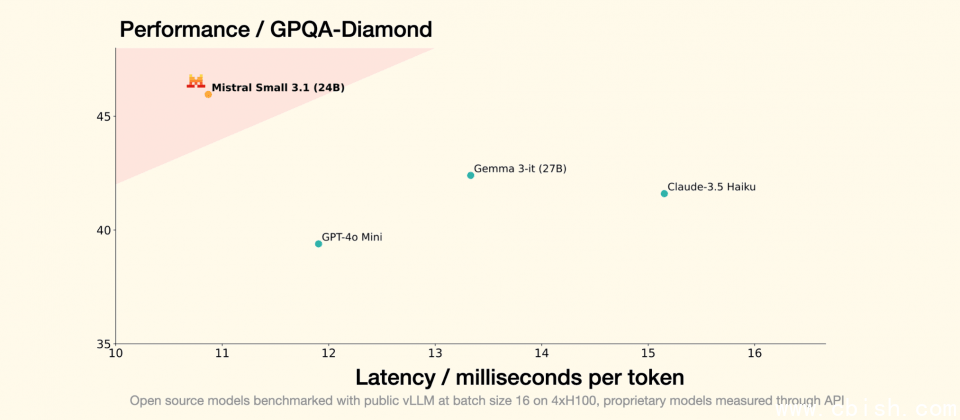
从Mistral AI公开的详细基準测试资料来看,Mistral Small 3.1在进阶的文字理解与推理任务,例如GPQA Diamond上达到45.96%,领先Gemma 3的42.40%。此外,程序撰写能力测试人类评估HumanEval中,Mistral Small 3.1表现达88.41%,同样略胜Gemma 3的87.80%。
视觉处理的效能差距则更为明显,根据ChartQA图表理解基準,Mistral Small 3.1取得86.24%的準确率,明显优于Gemma 3的78.00%。同时在文件图像理解测试DocVQA,Mistral Small 3.1也以94.08%的高準确率,领先Gemma 3的86.60%,这对于需要高度视觉理解能力的应用,例如自动文件分析、品质检测等相对重要。
然而,在数学推理方面则是Gemma 3表现亮眼,在MATH测试中,其準确率达89.00%,显着领先Mistral Small 3.1的69.30%。
另一个值得关注的是长上下文理解能力,Mistral Small 3.1可处理的上下文範围为12.8万Token,这使模型更适合处理大型文件或长对话场景。在专门用于评估长上下文处理能力的RULER 128K测试中,Mistral Small 3.1达到了81.20%的效能,而Gemma 3仅有66.00%。
在实际部署与硬件相容性方面,Mistral Small 3.1 24B与Gemma 3 27B针对单卡GPU装置最佳化,因此企业或研究团队不需要使用昂贵的丛集设备,即可实现高效推理运算,这点对于个人开发者、中小企业或需处理敏感资料且不愿将资料传输至云端的组织尤其重要。