 图片来源:
图片来源: Hugging Face
继于6月释出Gemma 2,提供9B及27B两种版本之后,Google周三(7/31)再接再励开源了Gemma 2 2B,并宣称此一小型模型在聊天机器人(Chatbot)评测上超越所有GPT-3.5模型。同一天Google还开源了安全内容分类模型ShieldGemma,以及可用来解释模型内部作业的Gemma Scope。
Google在今年2月开源的Gemma属于轻量级模型,但採用与大型语言模型Gemini一致的研究及技术,可于高阶游戏笔电、高阶桌上型电脑,以及云端上执行。
而Gemma 2 2B则是Gemma 2模型家族中最小的模型,是藉由蒸馏从更大的模型中学习,而取得了超乎其规模的杰出成果,它不仅超越其它同样大小的开源模型的表现,也在LMSYS Chatbot Arena Leaderboard上超越了所有GPT-3.5 模型,展示其强大的对话式AI能力。
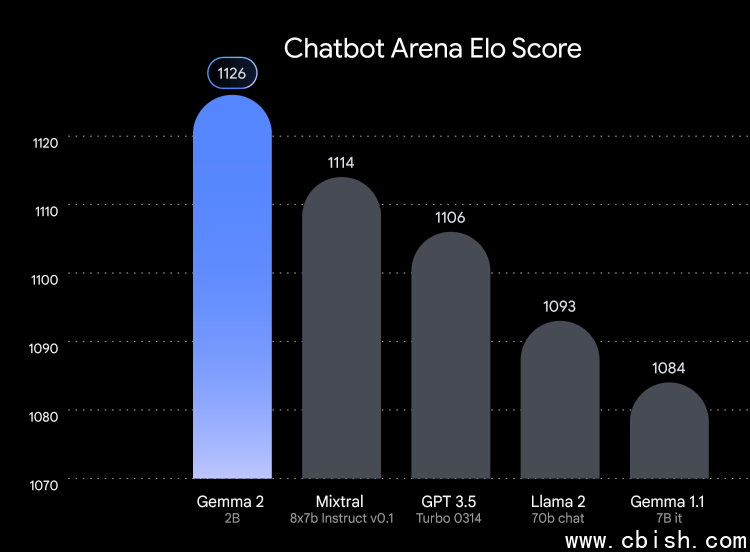
Google亦强调了Gemma 2 2B的灵活部署能力,可支援边缘装置、笔电,以及使用 Vertex AI与Google Kubernetes Engine(GKE)的强大云端部署,而为了进一步提升其速度,利用Nvidia TensorRT-LLM函式库进行最佳化,并可作为Nvidia NIM使用。
此一最佳化适用于各种不同部署,涵盖资料中心、云端、本地工作站、个人电脑与边缘装置,并利用Nvidia RTX、Nvidia GeForce RTX GPU或Nvidia的Jetson模组来执行边缘AI,也能在Google Colab平台上免费的T4 GPU上执行。另外它也能无缝整合Keras、JAX、Hugging Face、Nvidia NeMo、Ollama、Gemma.cpp 以及即将支援的MediaPipe,以简化开发。
至于ShieldGemma则是个安全分类模型,可额外部署在模型的输入及输出端,用以过滤有害内容,它主要筛选4大领域的内容,包括仇恨言论、骚扰、裸露的色情内容,以及危险内容。
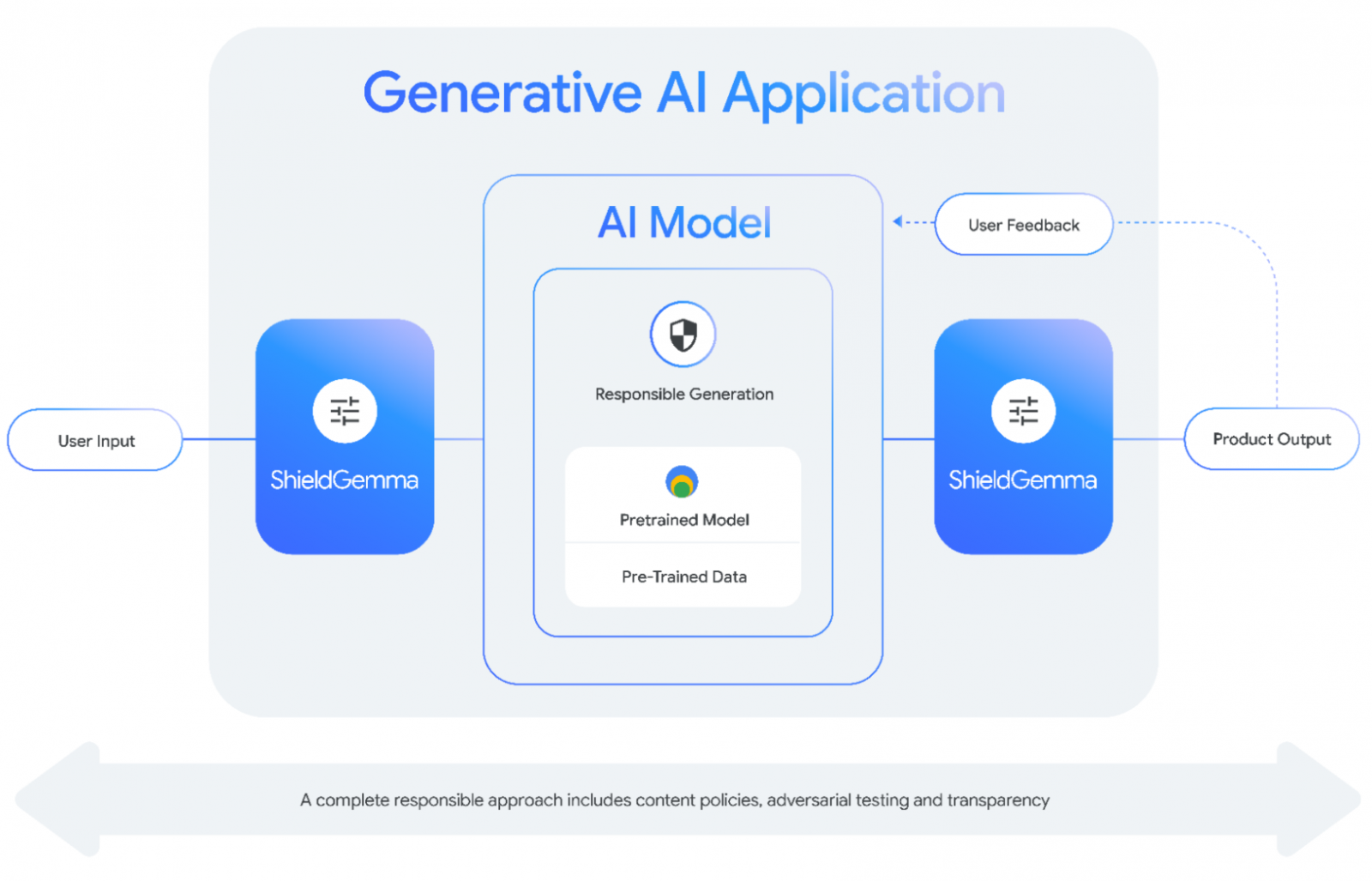
ShieldGemma具备2B、9B与27B版本以供开发者选择,其中,尺寸较小的ShieldGemma 2B最适合线上分类,9B与27B则相对适合较无延迟考量的离线应用。
本周开源的还有稀疏自动编码器(Sparse Autoencoder,SAE)Gemma Scope。Google是在Gemma 2 9B及Gemma 2 2B的每一层及子层输出上训练稀疏自动编码器,製造了超过400个SAE,具备逾3,000万个特徵,而Gemma Scope即是这些SAE的集合。

SAE为一特殊的神经网路,可于资料中找到有用的特徵,因此,ShieldGemma将协助研究人员理解特徵在模型中的演变、相互作用,或是如何形成更複杂的特徵,解读Gemma 2所处理的密集与複杂资讯,进一步透明化相关模型的内部作业。
美国商务部旗下的国家电信暨资讯管理局(NTIA)日前才发布政策建议,指出开放权重的模型允许开发者利用既有的基础建置与调整,把AI工具的可用性延伸至小公司、研究人员、非营利组织与个人,将拥抱AI的开放性,但也应该积极监控强大AI模型的安全风险。