专门开发轻量级、专业化生成式人工智慧模型的公司Mistral AI,升级了其程序码生成模型Codestral,新的Codestral 25.01版本在处理上下文长度,及程序码完成效率方面表现更好,且该模型上下文长度可达到25.6万Token,能有效满足大型专案和複杂程序码的完成需求。
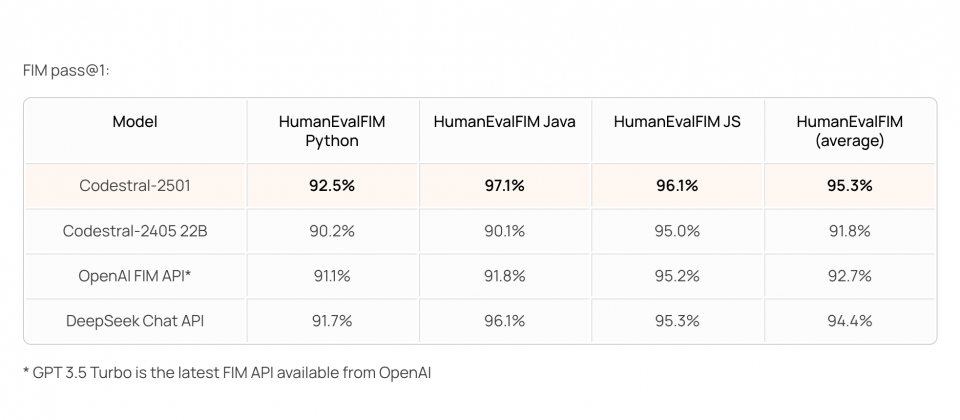
Mistral对少于1,000亿参数的程序码完成模型进行测试,Codestral 25.01在Fill-In-the-Middle(FIM)任务的表现,刷新了多项基準测试纪录。在HumanEval、MBPP和CruxEval等评估中,该模型在準确率和生成速度方面表现突出,特别是在FIM的Pass@1测试中,平均通过率达95.3%,显示其在单行程序码插入和完成的能力。与上一代Codestral 24.05相比,新版的程序码生成速度约是2倍,同时在多语言支援与程序码生成的準确性有明显进步。
与其他模型相比,Codestral 25.01在重要指标表现较佳,像是Meta的Codellama 70B instruct,虽然具通用性与多语言支持,但上下文长度仅有4,000个Token,难以满足处理大型专案的需求。此外,Codellama在FIM测试中的準确率也低于Codestral。
其他竞争者DeepSeek Coder系列模型,包括DeepSeek Coder 33B instruct和DeepSeek Coder V2 lite,其中后者在上下文长度方面提升至12.8万个Token,但整体性能落后于Codestral 25.01,像是HumanEval测试结果DeepSeek系列的表现皆不如Codestral。而OpenAI的GPT 3.5 Turbo FIM API虽在FIM测试水準与Codestral相近,但其上下文长度仅为3万个Token,在大型专案的应用上将受限。
Codestral 25.01的升级重点还有对多语言环境的优化。Codestral 25.01支援超过80种程序语言,涵盖Python、Java、JavaScript等主流语言,在SQL和Bash等应用案例也有精準的生成能力。测试显示,该模型在HumanEval各语言测试中的平均準确率达71.4%,在Python等常用语言的表现更是遥遥领先。
在轻量级程序码完成模型领域中,Codestral 25.01展现良好应用潜力。目前开发者已可透过支援的IDE或云端平台试用Codestral 25.01,Mistral也提供Codestral 25.01 API支援,供用户整合至现有的开发环境中。