
US Foods是一间有250,000间餐饮客户的美国大型食品经销商。旗下3,000名业务人员,不只要负责推销公司产品,还得扮演餐饮及开店顾问。每当餐厅提出谘询需求,业务人员就得花上3至4小时,彙整餐厅提供资料,再查找自家内部资料作为参考,才能开始製作顾问提案。平均,一名业务要负责50至70间餐厅。不只工作时间,连下班和假日,都被这些数据整理作业佔满。
直到今年,US Foods ML工程部门打造了一套生成式AI知识管理助手,来支援业务人员的数据彙整作业,成功将原本3至4小时费时,大幅缩短到半小时以内,带来超过6倍效率。这个KM助手前端是一个用React做的Web App,后端串接一系列数据处理模组及多模态LLM,来处理餐厅资料、比对US Foods内部资料,并提供业务人员製作顾问提案的建议。
US Foods ML工程部门副总David Falck揭露此KM助手的开发及维运细节。他强调,这个KM助手能达到如此成效,关键是不畏惧GAI準确度低,早早将雏形投入大规模真人试用。
不必过度在意準确度,实用性才是首要目标
如何降低生成式AI产生幻觉或回答不精确的机率,是企业应用此技术到实际业务流程中,一个常见品质控管环节。不过,David Falck表示:「我们打造KM助手学到的最大心得,就是不要太担心準确度。应该聚焦实用性,尽早让实际使用者告诉我们,工具好不好用。」
早在ML工程部门从GAI专案发想阶段,就开始注重实用性。
生成式AI爆红时,他们便决定大展身手,要从头建置一套只有US Foods IT能打造的GAI应用,来解决专属US Foods的业务痛点。他们开始四处访谈,寻找不同部门中,有哪些最麻烦的作业,适合用生成式AI解决。
David Falck表示,他们最后锁定业务人员餐饮顾问来打造GAI应用,是因为业务整理资料的流程枯燥费时、高度人工化,且需要处理手写纸条、食物图片、菜单等纸本非结构化资料。这便是生成式AI技术适合应对,且能发挥实用价值的好案例。
到了第一次大型验收,开发中的KM助手还远远不够成熟,回答準确率只有5至6成,连介面都非常阳春。不过,当业务主管们看到这个工具雏形,还是爱不释手。David Falck观察,对业务们来说,就算GAI工具回答精确度不高,还是能协助他们整理数据,发挥节省时间的实用价值。
这次经验,也使ML工程部门更放心的让更多第一线使用者试用这套KM助手。之后开发期间,他们逐步让更多市场及地区的业务人员试用。「準确率迟早会提升,使用者回馈要趁早蒐集。」David Falck表示,这个做法使他们能尽快测试和发挥实际工具成效,更能根据大量第一线使用者的诚实回馈,锁定优化方向。正式上线时,KM助手已经可以将3至4小时的资料整理时间,减少到20至30分钟。
持续优化和维运企业级应用的技术决策
David Falck说,ML工程团队的技术决策,有助于快速分析试用结果和使用者回馈,并弹性调整系统。KM助手正式上线后,这些决策则使他们能在3,000名使用者同时使用的情况下,持续迭代、维运系统,并控管公有云支出。
贯穿许多技术做法的两大原则是模组化与文件化。David Falck进一步说明,模组化不只是将不同功能串起来,更要妥善把不同功能和环节切割成独立模组。
开发过程中,US Foods团队深刻体会了,妥善切割功能模组的重要性。KM助手的其中一段后端资讯流是,利用Textract OCR模组,来将餐厅提供资讯的图文转化成文字,再抛转给LLM解析。David Falck回忆,某次他们尝试用多模态LLM的图文处理能力,来一口气将餐厅提供资讯的图文转化成文字、比对内部数据、产出建议。结果,但KM助手最终生成结果不如预期时,他们无法判别,究竟是餐厅资讯转化环节出错,提示工程有误,还是LLM解析资讯能力不足。最终,团队回归原本做法,将不同环节的功能独立成不同模组,不仅方便排错,也确保LLM更新时,不会一口气影响到太多数据处理环节。
连输入KM助手的提示词,他们都採取模组化做法。David Falck解释,採用模组化且简短的提示词,能提升模型推论结果的一致性与準确性,避免业务天南地北的询问,既造成额外支出又降低工具使用效率。「当未来代理型AI工具更加成熟,管理提示词的经验和工具也派得上用场。」
David Falck口中的文件化做法,则包括製作技术文件、为重要系统活动留存易分析的纪录,以及为使用者撰写系统功能说明书。
模组化提示词做法,也是ML工程团队文件化做法的一环。他们会记录和分析,KM工具使用接收不同提示词模板后,各自生成内容精确度和使用者满意度。这有助于他们持续优化提示词设计。
另一个做法是设置专门储存AI推论内容的资料库。David Falck解释,有许多业务询问AI的问题,答案不会随着时间而改变。类似问题只要有问过一次,之后都可从此资料库找到答案,不需呼叫模型API。如此可以降低成本、加速系统回答效率。纪录过往推论内容,更能让ML团队进一步比较不同AI模型版本间的问答内容,或研究AI回答不精确的原因。
他们还为KM助手的功能撰写详细功能说明书,让使用者能根据需求快速找到最适合功能,进而鼓励他们重複使用每一个功能组件。
除了上述KM助手的技术做法,David Falck强调,US Foods之所以能顺利打造实用的生成式AI应用,平时基本功做足更是先决条件。这包括维持企业数据高可用性、随时注重数据隐私及法遵措施、惯于控管云端支出,以及重複使用模组化数据处理功能。「生成式AI只是你软件开发百宝箱里的另一个技术,平时该注重的最佳IT实践方法,做GAI应用时也要做好。」他说。
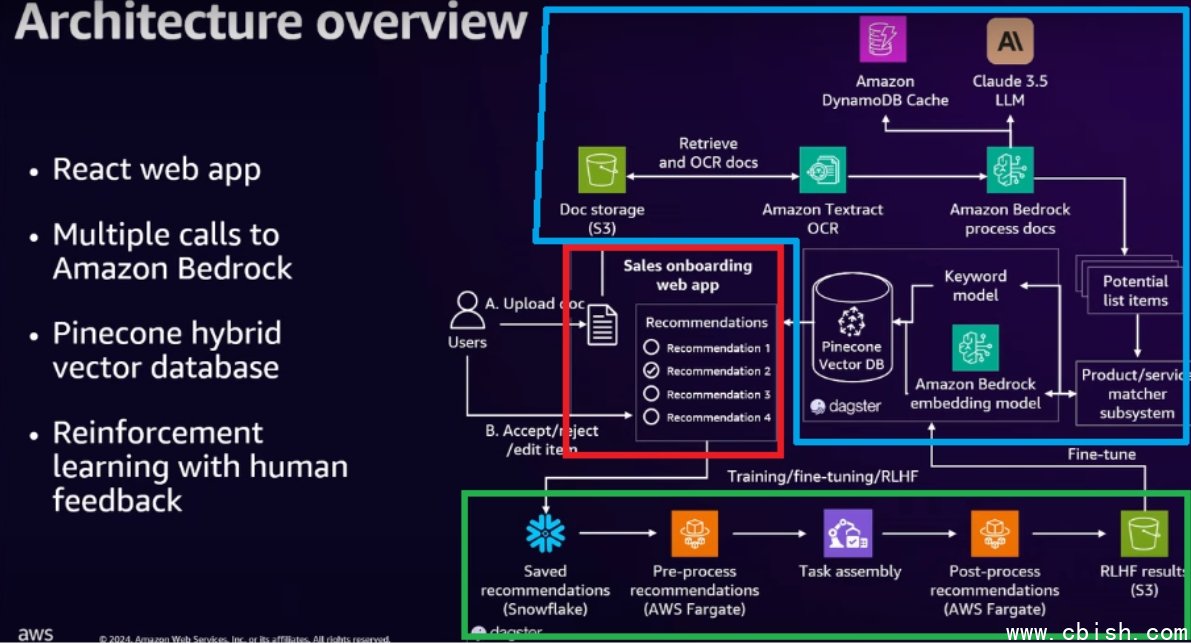
US Foods生成式AI业务助手的系统架构图。红色框是前端App,业务输入客户文件及需求(A动作)后,资料走到后端的推论流程(蓝色框),经过OCR模组、LLM模组、企业数据匹配模组等模组,产出推荐内容。业务会选择接受、不接受、或调整建议(B动作)。业务的选择,则会进入后端的真人回馈流程(绿色框),自动化、系统化的蒐集真人回馈,用来微调AI模型,提升回答品质。
此工具后端有两个重要资料库,分别提升生成速度及生成準确度。推论结果资料库会储存过往AI推论结果,后续类似问答不须模型重新推论,而是从资料库中提取,提升速度。混合向量资料库则支援混合式搜寻(Hybrid Search),使系统能更好的匹配企业客户提供的资料与所需企业内部数据,进一步提升生成精準度。