
背景图片取自Visax on Unsplash
在微软、Meta、Google等相继公布AI模型后,苹果终于发声,宣布并开源可在苹果装置端执行的AI模型OpenELM家族以及训练及推论框架,最小版本仅2.7亿参数。
OpenELM全名为开源高效语言模型(Open-source Efficient Language Model),苹果已在Hugging Face公开了4种参数规模的模型,涵括2.7亿、4.5亿、11亿及30亿,但每个规模又分成预训练及指令调校版本,因此OpenELM提供了8种版本。苹果的开源提供完整训练和评估框架,也提供将模型转换成MLX函式库的程式码,以便开发人员在苹果装置上推论和微调。

在训练方面,OpenELM模型是以CoreNet函式库作为训练框架,其预训练资料集包含了RefinedWeb、去除重覆资料的PILE、RedPajama和Dolma v1.6各一个子资料集,共1.8兆token。苹果说明,OpenELM融合了分层扩展策略,能将模型参数有效分配到transformer模型各层,以提升準确率。举例而言,11亿参数版本的OpenELM準确率较(12亿参数版本的)OLMo準确率高出2.36%,但预训练资料token仅其一半。
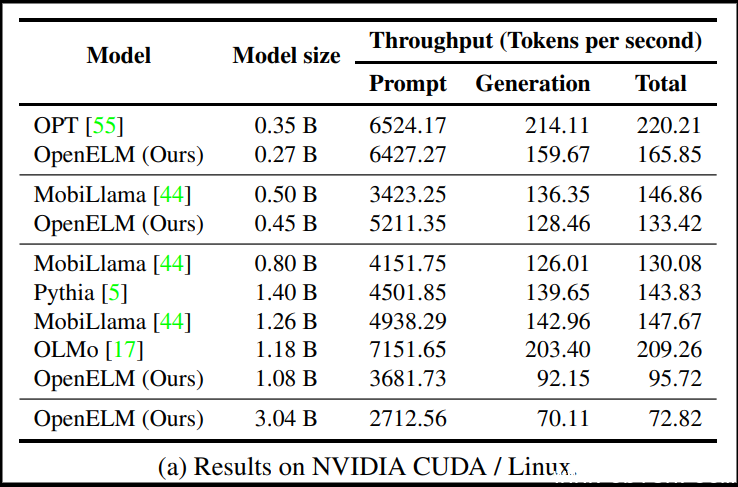
苹果也列出在一台Nvidia GPU/Ubuntu笔电上进行提示执行及程式码生成二个任务上,和其他开源模型的效能比较(如下图)。数据显示OpenELM 4.5亿参数版本在提示执行效能已超过MobiLama,2.7亿参数版本比起OPT也相差不远,但在程式码生成任务上,各个版本都还有待加强。苹果也列出了在Apple Silicon-based MacBook Pro上各版本OpenELM的执行数据。
这是苹果继去年十月悄悄开源多模语言模型Ferret及3月的MM1之后,再度公布的AI研发成果。但这次更为特别的是,OpenELM是可在苹果装置上执行的语言模型。本周稍早微软也释出了可在笔电上执行的小语言模型(SLM)Phi-3系列,最小版本为38亿参数。微软强调Phi-3在语言理解、推理、数学及写程式等能力上,比更多参数的模型如GPT-3.5 Turbo、Mistral还强大
苹果与其他晶片业者包括英特尔、AMD、高通等,都可望在今年推出为AI模型执行设计的第一代或新一代晶片。最新Apple Silicon为M4,预计今年稍后问世,并在年底推出搭载M4晶片的Mac产品。