Nvidia昨日宣布推出新一代Nemotron 3开源模型家族,包含Nano、Super和Ultra三个版本,以及配套的工具和数据集。该系列模型采用创新的混合专家(MoE)架构,显著提升准确率,专为开发代理式AI应用而设计。
Nvidia强调,Nemotron 3家族融合了Mamba-Transformer混合专家(hybrid mixture-of-experts, MoE)架构、交互环境中的强化学习(reinforcement learning, RL)以及原生100万token上下文长度能力,可支持多代理系统执行高吞吐量、长视野推理任务。Nvidia同时开放了模型权重、训练数据集、训练方法及框架。
通过创新的Mamba-Transformer架构,Nemotron 3实现了100万token的上下文长度,能够支持大型代码库、超长文档、连续对话以及跨来源信息整合,使模型首次能够在完整数据基础上进行持续、连贯的推理,不再依赖以往碎片化、拼接和反复遗忘的处理方式。
技术层面,Mamba层擅长捕捉长程依赖关系,内存占用极低,在处理数十万token时仍保持高效,特别适合长文本推理与序列建模;Transformer层则通过精细的注意力机制,精准捕捉程序操作、数学推理和复杂逻辑等任务所需的结构关系;而MoE架构可在不增加密集计算成本的前提下高效激活参数,大幅提升大规模运算效率。
Nemotron 3在后训练阶段通过NeMo Gym平台应用强化学习,评估并优化模型执行真实代理行为的能力,例如调用正确工具、编写功能代码、生成多步骤规划等。
Nemotron 3家族中,Nano为300亿参数的小型模型,单次推理最多激活30亿参数,强调低计算成本与高效率;Super为近1000亿参数的高精度推理模型,单个token最多激活100亿参数,适用于多代理应用场景;Ultra则为约5000亿参数的大型推理引擎,单token可激活500亿参数,专为需要深度研究与策略规划的高复杂性AI任务设计。
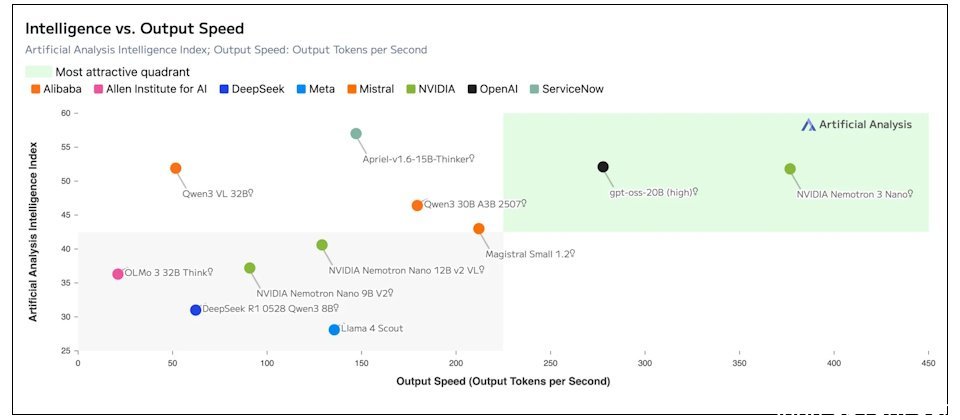
最小的Nemotron 3 Nano现已在Hugging Face上线,针对软件调试、内容摘要、AI助手工作流及信息提取等任务优化。相比前代Nano模型,其每秒token吞吐量提升4倍,推理生成token数量最高减少60%,显著降低推理成本。100万token的上下文长度使其能更精准地串联多步骤任务中的信息。
Nvidia表示,Nemotron 3 Nano在多项基准测试中表现优于Qwen3-30B和GPT-OSS-20B。