资料来源:AIxCC,iThome整理,2025年10月
用AI挖掘漏洞今年迈入新里程,相关重要发展,可追溯至2023年,美国白宫宣布举行AI网络挑战赛(AIxCC),当时共有42支队伍报名参赛,目标是设计AI驱动的网络推理系统(Cyber Reasoning System,CRS),发展可自动发现与修补漏洞的解决方案。
这项赛事历经两年的比拼,今年8月,美国国防高等研究计划署(DARPA)公布最终成绩,并揭示决赛带来的重大成果,自动修补能力成为最新关注焦点。
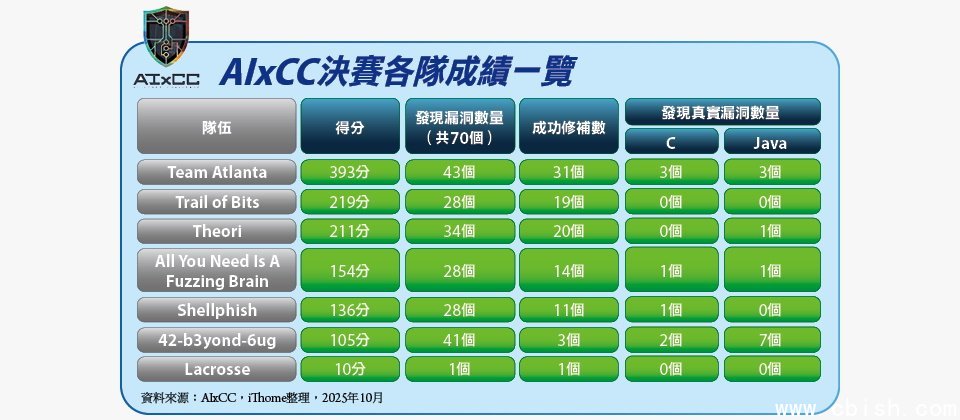
AIxCC竞赛最终成绩揭晓,第一名队伍为Team Atlanta
基本上,在2025年决赛挑战项目中,主要聚焦C与Java的编程语言漏洞计分,主办方总共设计了70个刻意设计的合成漏洞(synthetic vulnerabilities),让7支决赛团队设计的CRS系统,来自动发现漏洞并提出修补方案。
第一名是在决赛中获得393分的「Team Atlanta」,其成员来自美国乔治亚理工学院、三星研究院、韩国科学技术院(KAIST),以及浦项科技大学(POSTECH)。
他们的CRS系统可发现43个合成漏洞,并成功修补31个。不仅如此,还额外发现了6个零时差漏洞,其中3个存在于C语言,3个存在于Java语言。
第二名是获得219分的「Trail of Bits」,是来自纽约的小型企业团队,成绩不俗,设计的CRS系统能发现28个合成漏洞,成功修补19个漏洞。
第三名是获得211分的「Theori」,由美国与韩国的AI研究者与安全专业人员组成,他们的CRS系统发现34个合成漏洞,并成功修补20个漏洞,而且另外找到一个Java的零时差漏洞。
不只上述3队表现出色,就连排名第6的「42-b3yond-6ug」,表现也很抢眼,该队伍虽然只获得105分,但其打造的CRS系统能发现41个漏洞,并成功修补3个,甚至还额外发现了9个零时差漏洞,其中2个在C语言,7个在Java语言。
AIxCC决赛7强的CRS系统已全部开源释出!

AIxCC挑战赛的落幕并非终点,DARPA要求所有决赛队伍都要在赛后开源其成果,这将让全球乃至中国大陆的安全研究社群与产业,都能在此基础上更深入研究、验证与创新,加速AI驱动防御技术的应用落地与发展。
AIxCC决赛新转变,更看重发展AI自动生成修补的能力
关注AIxCC参赛队伍的名次之余,从上述决赛的得分,我们发现决赛的关键不仅在于找出漏洞,更在于能否有效修补。因为,主办方DARPA明显将「高质量修补」列为评分核心,其权重甚至高于漏洞发现。
以冠军队伍Team Atlanta为例,能从众多参赛队伍中脱颖而出,除了找出43个漏洞,更成功修补其中31个,最终累积393分。相比之下,第6名队伍虽然同样发现超过40个漏洞,但成功修补的只有3个,得分为105分。换句话说,我们可以发现修补效率的差距,成为决定这次胜负的关键。
事实上,AIxCC的设计初衷,也正是促使AI系统不只自动发现漏洞,还要能提供不破坏功能的修补方案。而在确认AI自动修补的可行性后,决赛计分权重也做出改变,聚焦品质与可靠性。
今年的决赛有哪些重要改变?简单而言,决赛内容可分成full-scan与delta-scan两种形式,而根据第二名Trail of Bits团队的分享,决赛期间共有48回挑战,涵盖23个开源仓库。
至于决赛总分的计算,据DARPA指出,主要是由「准确率加权系数」乘以各项表现指标而得,包括「漏洞发现分数」、「程序修补分数」、「SARIF评估分数」与「关联度分数」。
我们认为当中最重要的变化是,每个成功修补的得分权重,是成功漏洞发现的3倍。换句话说,1次正确修补可抵3次漏洞发现。而且这两项分数计算皆纳入时间系数,完成得越快,得分也越高,等于也有鼓励快速修补的意味。
同时,这次还加入SARIF评估与关联度的分数,前者反映AI对漏洞报告的理解与判断能力,后者衡量能否正确关联漏洞与修补的能力。再加上准确率加权机制,也就是系统提交越少的错误结果或重复结果,整体得分将会越高。
综上所述,这些计分机制均凸显出,AIxCC不只强调找出漏洞,更强调修补漏洞,并重视速度、精准度与稳定性。
「高质量修补,是这场竞赛一项重要成就。」AIxCC项目经理Andrew Carney在公布决赛结果时特别提及此事,他并观察到,各队CRS系统在挖掘漏洞的过程中,其实也促进了修补程序的开发。
言下之意是:CRS系统在分析漏洞时,其推理过程不仅有助于识别弱点,也能深入理解漏洞的成因与修补逻辑,从而生成更贴近实际问题、质量更高的修补方案。
综合来看,随着AIxCC竞赛的推进,也显示当今应对漏洞策略的变化:从利用AI发现漏洞,推进到重视修补质量与实用性。
修补速度、成本效益的展现,同样成为决赛比拼的一大亮点
值得一提的是,DARPA还公布决赛的一些亮点,例如,这7支决赛团队的CRS系统,总共分析超过5,400万行代码;每支队伍都识别出一个零时差漏洞。
不过,根据最终成绩资料,仅有5支队伍发现真实的零时差漏洞。我们推测,DARPA此处所指的「识别」,应是指7支决赛队伍的系统皆识别出含真实漏洞的代码区段,但仅有5支队伍提交出可验证的漏洞报告。
在修补成果方面,DARPA指出,各队提交修补的平均时间为45分钟,而且有1支队伍的成功修补是长度超过300行,也有4支队伍生成只需一行代码更改的成功修补。
在成本效益上,DARPA特别强调,有队伍在处理每个竞赛任务的平均花费仅约152美元,展现自动化漏洞发现与修补带来显著的成本效益。
而且,为了突显这项价值的差异有多大,DARPA特别以传统漏洞奖励计划(Bug Bounty)作为对比,指出后者往往需支付数十万美元不等的奖金成本,以彰显CRS系统的可贵之处。
尽管这样的比较是否完全等价,外界可能有不同的看法,但我们认为,单就考量成本这个因素而言,就是提醒大家:不仅要在技术上追求AI的准确度与修补质量,也要考量实际应用的成本效益与可持续性,才能让解决方案能够大规模落地应用。
若进一步检视决赛规则,我们可以发现DARPA在成本方面的限制与规范。
例如,为了确保公平竞争,以及反映AI系统在现实企业环境下的运作条件,DARPA针对所有决赛队伍提供两大类预算资源,包括:Azure订阅预算,以及LLM使用预算。
以Azure订阅预算而言,微软是技术合作伙伴,由主办方DARPA统一提供这项云端资源,给予每支决赛队伍10万美元的开发预算,可用于部署、训练与测试CRS系统;到了决赛,主办方另外提供专用的环境与独立预算,挑战期间如超出Azure预算上限,之后的提交将不计入得分。
以LLM订阅预算而言,这方面来源,主要由Anthropic、Google、OpenAI各赞助35万美元的使用额度,由主办方统一发放API密钥,供各队使用Claude、Gemini、GPT等模型。而在决赛中,每队LLM使用配额是5万美元,若是超出,该队后续提交成果也不列入得分。
换句话说,这项预算制度不仅确保了竞赛的公平,并期盼参赛队伍在可控成本内,验证AI自动推理系统的实际效能与可扩展性。
整体而言,为了解决潜在漏洞问题,过去模糊测试(Fuzzing)技术已经带来帮助,最近几年,随着LLM与生成式AI技术迅速发展,我们更需运用AI技术,找出连Fuzzing也难以发现的深层漏洞。
回顾AIxCC半决赛到决赛的结果,我们很高兴可以看到,合成漏洞发现率已经显著提升,从37%到77%,这证明了 AI 的巨大潜力。然而,这份成果也提醒我们,未来仍有巨大的空间等待我们去开拓和突破。
同时,全球产业亦相当重视修补过程中的「速度」、「成本」与「质量」,这些关键要素的进展,将让AI自动发现漏洞更具备实用价值,一旦做到比人工方式更快、更便宜,而且更准确可靠,才真正能为世界带来改变,这正是接下来我们要持续努力的方向。
从CGC到AIxCC,自动化防御迈向新世代
早在AIxCC挑战赛出现的10年前,美国国防高等研究计划署(DARPA)曾在2014年宣布举办「Cyber Grand Challenge(CGC)」,这是全球第一个以全自动化安全防御系统为目标的竞赛,目的在于推动机器在无人干预的情况下,能够分析推理漏洞与制定修补。
当时CGC竞赛被视为一次大胆的实验:主办方设定理论上可行、但实际上极具挑战性的问题——设想电脑是否能在没有人类介入下,主动找出软件弱点并进行防御。2016年决赛就是全自动、电脑对电脑的CTF夺旗赛,让参赛系统自动攻防、修补漏洞,展现了自动化防御的雏形。
不过,与今日相比,当时CGC挑战赛的参赛团队,运用技术主要聚焦采用符号执行(Symbolic Execution),以及模糊测试(Fuzzing)等作为核心。
而在2023年启动的AI网络挑战赛(AIxCC),是在既有技术发展上,并将重点转向于引入LLM、生成式AI,期望这项赛事能探索利用这些最新技术,进而发现更深层的漏洞并生成修补方案。
甚至到了2025年决赛进行期间,还有AI代理(Agent)的全新应用出炉,而这样的演进也呼应参赛队伍的CRS系统,逐步朝向具备自主决策能力的自主代理(autonomous agents)方向发展。
