浏览器本地运行Gemma 4,免费手绘流程图,彻底告别Token焦虑
admin 2026-04-27 202浏览
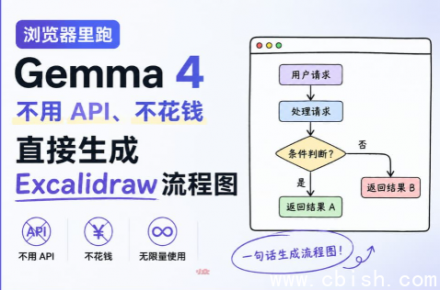
浏览器也能跑大模型?Gemma4 现在直接在 Chrome 里干活 你可能以为AI模型都得靠云端、要登录账号、扣积分,但现在,一个叫Gemma4的模型,已经能直接在你的浏览器里跑起来了。不需要安...
admin 2026-04-27 202浏览
浏览器也能跑大模型?Gemma4 现在直接在 Chrome 里干活 你可能以为AI模型都得靠云端、要登录账号、扣积分,但现在,一个叫Gemma4的模型,已经能直接在你的浏览器里跑起来了。不需要安...

admin 2026-03-27 157浏览
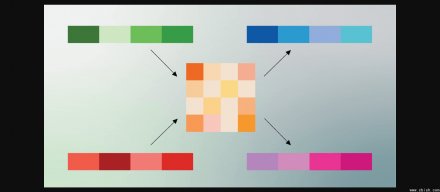
谷歌新算法让大模型跑得更快、更省电 3月26日,谷歌研究团队正式发布了一项名为 TurboQuant 的新技术,专门解决大语言模型(LLM)在处理长文本时“内存吃不消”的老问题。简单说,它...
admin 2026-03-27 167浏览
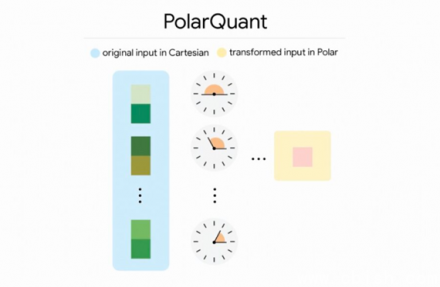
谷歌研究团队发布TurboQuant,将该量化方法应用于大语言模型的KV缓存与向量搜索压缩。该研究旨在解决高维向量在推理与检索过程中占用大量内存,进而推高缓存与相似度搜索成本的问...
admin 2026-03-26 134浏览
内存太慢?谷歌新方案让大模型跑得更快、更省 你有没有遇到过这样的情况:问AI一个长问题,它卡几秒才回复;或者在手机上用大模型App,用几分钟就发热、掉帧?问题不在模型不够...