新浪开源VibeThinker-3B模型:30亿参数探索轻量化推理路径
人工智能模型的参数量并非越大越好。新浪团队近日开源的VibeThinker-3B模型提供了新的参照。该模型仅含30亿参数,在数学与编程等高难度基准测试中,性能已对标主流百倍规模大模型。部分竞赛级任务的成绩甚至超过了多款行业头部产品。
VibeThinker-3B以阿里Qwen2.5-Coder-3B为基底。研发团队采用多阶段精细化后训练策略,涵盖监督微调、强化学习、自蒸馏及指令微调等环节。逻辑推理能力被深度浓缩至3B轻量化架构中。
测试数据显示,该模型在LeetCode竞赛题目中高效完成128道中的123道。这一成绩已超越GPT-5.2。
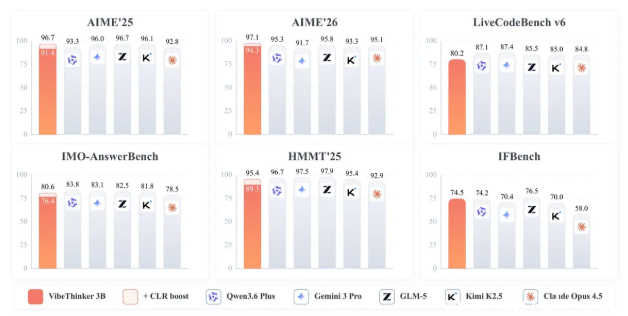
研发团队同步提出“参数压缩-覆盖假说”。人工智能的能力分布并不均匀。结构清晰的任务如逻辑推理与编程运算,可通过特定训练模式实现高密度压缩。广泛的世界知识储备则依然依赖庞大参数量支撑。推理任务未必需要随时调用成本昂贵的超大模型。
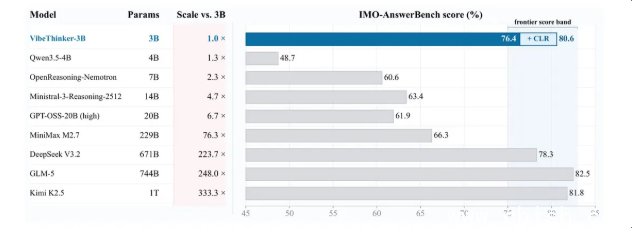
VibeThinker-3B已在Hugging Face与GitHub正式开源。这为开发者提供了一套轻量工具。在特定任务领域,精耕细作的后训练或许能以极低的算力成本,换取接近行业巨头模型的推理体验。