北大与DeepSeek开源大模型推理加速框架DSpark
大语言模型在高并发推理时,往往因为频繁执行前向计算导致响应变慢和算力浪费。北京大学与深度求索(DeepSeek)在6月28日联合发布开源框架DSpark,试图打破这一效率瓶颈。
标准的大模型生成流程采用自回归方式,每输出一个词元都要消耗完整算力,实时对话速度因此受限。推测解码是目前常见的提速方案,但实际存在短板。串行生成比较耗时,并行方案在处理长文本时,候选词接受率容易下降,大量算力会被无效消耗。
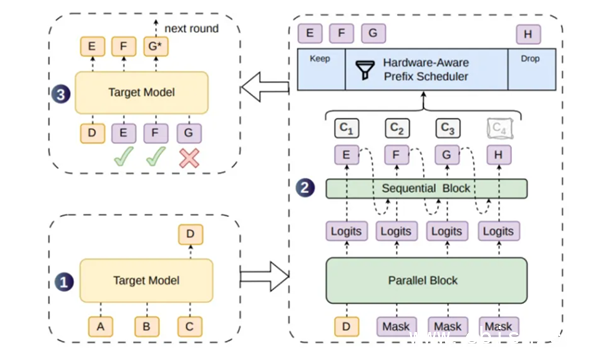
DSpark采用双重优化机制应对上述问题。候选生成阶段改用半自回归架构。系统通过并行主干网络一次性输出基础特征,再用轻量化模块梳理文本逻辑。该架构仅需两层Transformer结构,表现已优于传统的五层并行模型。在验证调度层面,框架加入置信度调度验证机制。硬件感知前缀调度器会实时评估算力负载,优先处理可靠性高的文本片段,从而减少无效计算。
研发团队在通义千问3、Gemma4等模型上进行了测试,覆盖代码编写、数学推理与日常对话场景。对比Eagle3和DFlash等主流基线,DSpark在单轮有效生成长度上更具优势,长序列任务中的候选有效率衰减问题得到缓解。
工程落地方面,系统进行了序列打包以降低内存占用,设计异步调度模式消除GPU流水线卡顿,并兼容主流CUDA硬件。目前DSpark已接入DeepSeek-V4-Flash与DeepSeek-V4-Pro预览版引擎。实测显示,系统整体吞吐量在不同响应速度标准下均有提升。
相关代码与工具已在GitHub DeepSpec项目开源,包含DSpark、DFlash及Eagle3的训练代码、模型权重与评估工具。该框架的开放旨在降低高性能推理服务的部署门槛,为大模型应用的低成本普及提供技术参考。