Anthropic 发布中端模型 Claude Sonnet 4.6,该新模型在代码生成、计算机操作、长文本推理与多步骤任务规划等核心能力上均有提升,定价与前代 Sonnet 4.5 保持一致,每百万输入令牌(Token)3美元,输出15美元。免费与付费用户现均可使用 Sonnet 4.6,并首次在 Sonnet 系列中引入百万令牌上下文窗口。
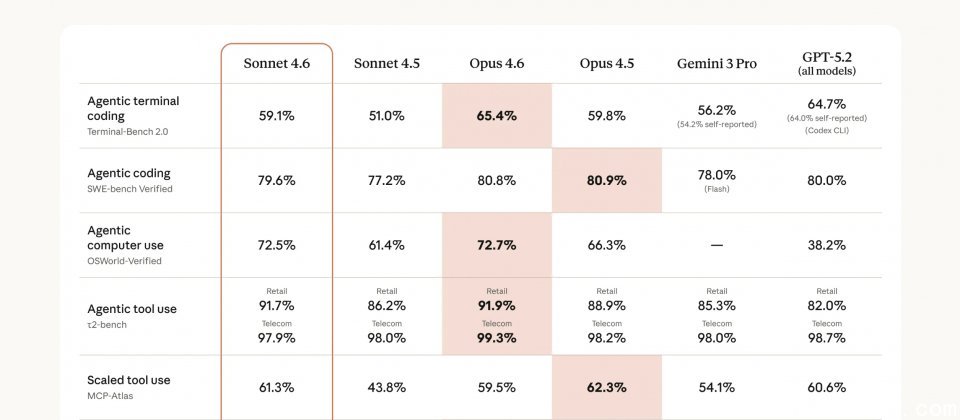
在代码辅助工具 Claude Code 的内部测评中,用户在70%的情况下更偏好 Sonnet 4.6 而非前代 Sonnet 4.5,更有59%的情况优于 Opus 4.5。官方引用用户反馈指出,Sonnet 4.6 在修改代码前更能理解既有上下文,倾向于整合共享逻辑而非重复实现;相比前一版本,较少出现过度设计、错误声称任务完成或幻觉输出,在多步骤任务中的指令遵循与执行一致性也显著改善。
计算机操作能力是 Claude Sonnet 4.6 的另一大重点,其在 OSWorld 基准测试中的得分较前代显著提升。用户观察到,其在复杂的电子表格操作与多步骤网页表单填写等任务中,已达到接近人类的水平。OSWorld 基准测试模拟真实计算机环境,要求模型在 Chrome、LibreOffice、VS Code 等软件中完成数百项任务,且不依赖特殊 API 或专属接口,模型需以接近人类的方式操作鼠标与键盘。
此外,Anthropic 表示,Sonnet 4.6 在对抗提示注入的防御能力上较 Sonnet 4.5 有大幅改善,表现与旗舰模型 Opus 4.6 相当。在上下文长度方面,Sonnet 4.6 提供百万令牌上下文窗口,可单次请求容纳大型代码库或数十份研究报告。不过,实际可用的上下文上限及启用条件将根据使用平台与账户权限而定。
Sonnet 4.6 在 Claude 开发者平台已支持上下文压缩(Context Compaction)功能,可在对话接近上下文上限时自动摘要较早内容,以延长有效使用长度。Anthropic 也更新了 API 的网络搜索与信息提取工具,新增动态过滤机制,使模型能自动编写并执行代码筛选结果,仅保留相关内容,以提升响应质量并降低令牌消耗。
Anthropic 说明,在需要最深层推理的场景下,例如大规模代码库重构或协调多个代理的复杂工作流程,目前仍推荐使用旗舰模型 Opus 4.6。Sonnet 4.6 的定位是在更广泛的应用场景中,提供接近旗舰级别的性能,同时维持有竞争力的成本结构。Claude Sonnet 4.6 现已在所有 Claude 方案、Claude Cowork、Claude Code、Anthropic API 及主要云平台上线。