Databricks旗下的Mosaic AI Research团队推出MemAlign,这是一套通过双记忆系统积累专家自然语言反馈的LLM评估对齐框架,并已集成到开源模型生命周期平台MLflow中,帮助企业LLM评估标准更贴近行业规范。开发团队指出,提示词工程在规则逐步增加后容易出现前后不一致、覆盖范围难以管控等问题,同时受限于上下文长度;而微调则需要较高的数据与时间成本。因此,MemAlign采用记忆机制,使评估标准能够随着反馈积累动态调整。
企业在引入生成式AI后,常使用LLM作为自动评估器,检查代理程序与客服机器人的输出是否安全、准确且符合规范。然而,这类通用评估器的判断往往与领域专家在实际应用中重视的质量标准不一致。Mosaic团队举例说明,模型可能仅根据措辞是否礼貌下结论,而忽略用户真实意图;也可能认为客服只要说明原因与处理周期就算合格,却未将先安抚情绪、使用支持性语气收尾等服务标准纳入评估体系。
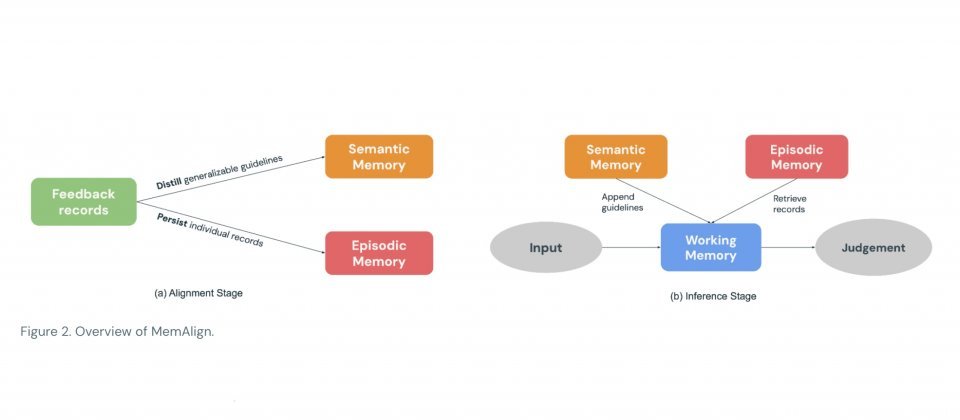
MemAlign采用双记忆架构,无需更新模型权重。系统会将专家以自然语言撰写的反馈提炼为可复用的评估原则,存入语义记忆;同时将难以用原则完整覆盖、且容易出错的具体案例保留在情景记忆中。当新输入到来时,MemAlign会先整合既有原则,并从情景记忆中检索相似案例,共同组成工作记忆作为本次评估的参考上下文,再交由LLM完成评分。记忆内容支持删除或覆盖,便于应对规定变更、需求调整或数据清理等场景。
在Prometheus-eval LLM评估基准的10个数据集上,团队仅使用最多50条反馈样本进行对齐。结果显示,在此设定下,MemAlign以约0.03美元的对齐成本、约40秒的对齐耗时达到最高评估质量。相比之下,DSPy系列提示词优化工具在同一对照实验中需消耗1至5美元成本,耗时9至85分钟才能完成一次对齐迭代。
Databricks提醒,推理阶段因需对记忆执行向量搜索,单次评估可能额外增加约0.8至1秒延迟。MLflow文档将MemAlign标记为实验性优化工具,提示接口可能调整,并建议在评估追踪记录中保留人工评估结果与自然语言理由,以便对齐过程有效吸收专家判断依据。Databricks表示,MemAlign现已可在开源MLflow及Databricks平台上使用。