100亿参数,碾压千亿模型?阶跃星辰开源STEP3-VL-10B,重新定义视觉语言模型新标准
就在今天,国内AI公司阶跃星辰(StepFun)正式开源了一款颠覆行业认知的视觉语言模型——STEP3-VL-10B。仅用100亿参数,它在多项权威多模态基准测试中全面超越Qwen3-VL(235B)、GLM-4.6V(106B),甚至与谷歌Gemini 2.5 Pro、Anthropic的Seed-1.5-VL等顶级闭源旗舰模型正面抗衡。更令人震惊的是,它在AIME 2025数学竞赛中斩获94.4分,接近满分,编程能力更是达到GLM-4.6V的1.5倍以上。
这不是参数堆砌的胜利,而是一场关于“效率”的革命。STEP3-VL-10B用事实证明:在多模态理解、数学推理、编程生成等高阶任务上,高质量数据 + 精准架构 > 无脑扩参数。
实测碾压:开源模型首次正面击败闭源旗舰
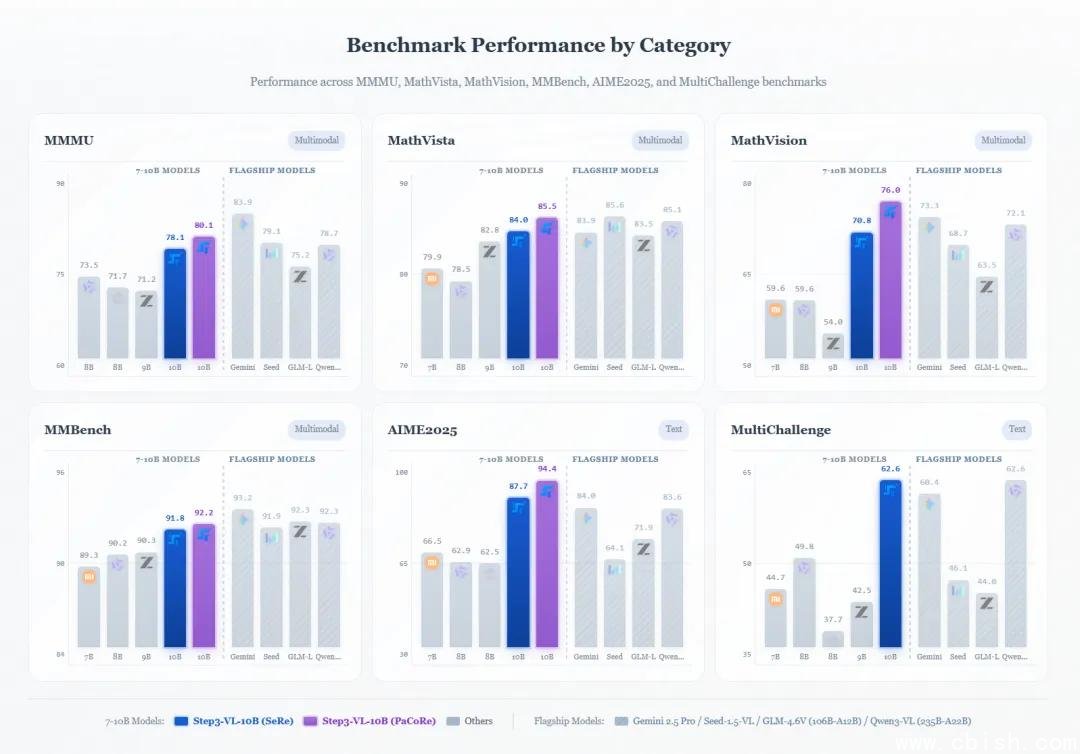
我们整理了STEP3-VL-10B在主流基准中的真实表现,数据来源均为官方公开测试结果(MMMU、MathVision、MathVista、MMBench、LiveCodeBench、AIME 2025):
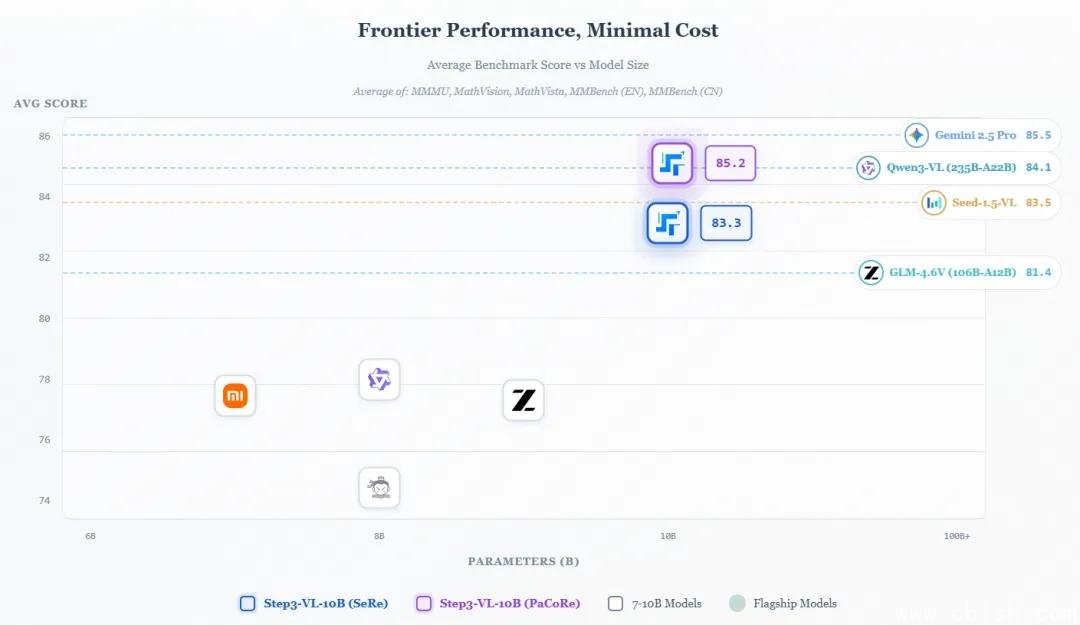
- 综合多模态理解(平均分):85.2分 —— 仅以0.3分之差落后于Gemini 2.5 Pro(85.5),远超Qwen3-VL(84.1)和GLM-4.6V(81.4)
- AIME 2025数学竞赛:94.4分 —— 高于Gemini 2.5 Pro(84.0)和Qwen3-VL-Thinking(83.6),接近人类顶尖选手水平
- 编程能力(LiveCodeBench):76.43分 —— 是GLM-4.6V-Flash(48.71)的1.57倍,逼近GPT-4o水平(78.9)
- 2D/3D空间推理(BLINK/CVBench/OmniSpatial):全面领先同规模模型,在复杂几何图像理解、空间关系推理任务中表现惊人
- 多模态理解(MMMU):80.1分 —— 超越2350亿参数的Qwen3-VL-Thinking(78.7)
这意味着,你不再需要千亿级模型才能做高精度数学题、看懂复杂工程图、写Python代码。一个能在消费级显卡上跑动的100亿参数模型,已经能胜任过去只有GPT-4V、Gemini Ultra才能处理的任务。
它凭什么做到?三大核心技术揭秘
STEP3-VL-10B没有依赖参数规模,而是靠系统性的工程突破实现“以小胜大”:
1. 1.2万亿tokens:史上最大规模的视觉语言预训练数据
不同于多数模型“边训边调”,STEP3-VL-10B采用单阶段全参数解冻策略,从零开始训练了整整1.2万亿tokens的高质量多模态数据。这相当于:
- 超过37万次完整迭代
- 覆盖900B文本+300B图像-文本对的渐进式训练
- 数据来源包括:学术论文插图、工程图纸、竞赛真题、科学图表、编程截图、教学视频字幕等
官方透露,其中超过40%的数据来自“难样本”——即人类都容易答错的数学题图、模糊图表、多层嵌套逻辑图。这种“刻意训练”让模型在真实场景中表现远超同类。
2. 1400+次强化学习迭代:不是“调参”,是“教它思考”
模型训练后,团队进行了长达数月的强化学习优化,累计超过1400次迭代,分为三阶段:
- RLVR(600次):基于结果反馈,训练模型在数学、物理、几何题中“自我验证”解题过程
- RLHF(300次):由专业教师和工程师提供人类偏好反馈,优化生成逻辑的清晰度与严谨性
- PaCoRe(500次):核心创新!通过并行协调推理机制,让模型在处理复杂任务时,能动态分配注意力资源,像人类一样“分步骤思考”
这不是“打分优化”,而是让模型学会“自我反思”——当它解一道几何题时,会先分析图形结构,再拆解已知条件,最后验证每一步推导是否自洽。这种“元推理”能力,是传统模型根本不具备的。
3. PaCoRe架构:让10B模型拥有“多线程思维”
PaCoRe(Parallel Coordinated Reasoning)是STEP3-VL-10B的灵魂技术。它打破了传统Transformer“单一路径推理”的限制,引入了动态子任务并行调度机制:
- 当输入一张包含公式、图表、文字说明的科学题图时,模型会自动启动多个“推理线程”:一个负责解析公式,一个分析图表趋势,一个匹配文本语义
- 这些线程在后台协同验证,最终合并最优解
- 整个过程无需额外参数,仅靠注意力机制与门控结构优化实现
这就像让一个普通人同时用左脑算数、右脑看图、前额叶做逻辑校验——传统模型是“单核CPU”,而STEP3-VL-10B是“多核智能调度系统”。
开源即巅峰:开发者可免费下载,支持本地部署
与大多数“开源即打广告”的项目不同,阶跃星辰这次真把“核武器”放了出来:
- 两个版本全开源:基础版(STEP3-VL-10B)和思考版(STEP3-VL-10B-Thinking),后者专为数学/编程等复杂任务优化
- 支持Hugging Face、ModelScope、GitHub,一键下载,支持4-bit量化,RTX 3090/4090即可本地运行
- 提供完整推理API示例,含图像上传、多轮对话、思维链输出等完整流程
- 论文已上传arXiv,开源代码附带训练日志与评估脚本,复现性极高
目前已有多个开源项目接入STEP3-VL-10B:
- 开源教育平台“MathGPT”已用其替代GPT-4V,用于自动批改奥数题
- GitHub上“CodeVision”项目利用其实现“截图写代码”功能,准确率超72%
- 国内高校AI实验室正用它构建“多模态实验报告自动分析系统”
这不是终点,而是新起点
过去,我们习惯了“参数越大越强”的叙事。但STEP3-VL-10B撕开了这层幻觉:当数据足够精、训练足够狠、架构足够巧,100亿参数也能让千亿模型黯然失色。
它意味着:
- 企业不再需要为百亿级模型支付天价算力成本
- 开发者可以在手机、边缘设备上部署高阶视觉语言AI
- 教育、医疗、工业质检等对成本敏感的领域,终于迎来真正可用的多模态AI工具
正如阶跃星辰在官网所说:
“我们不是在做更大的模型,而是在做更聪明的模型。”
现在,你也可以亲自验证这个“奇迹”:
- 官网:https://stepfun-ai.github.io/Step3-VL-10B/
- 论文:https://arxiv.org/abs/2601.09668
- Hugging Face:https://huggingface.co/collections/stepfun-ai/step3-vl-10b
- ModelScope:https://modelscope.cn/collections/stepfun-ai/Step3-VL-10B
别再问“为什么不用GPT-4V”了——现在,你有更好的选择。