当AI开始“进化”:一场发生在数字世界的红皇后竞赛
你有没有想过,人工智能之间也会像动物界那样“你追我赶”?不是人教它怎么赢,而是它们自己在不断对抗中,学会如何生存、适应、反击——就像地球上每一只猎豹必须跑得比羚羊快,每一只羚羊也必须跑得比猎豹更快。这,就是生物学中的“红皇后假说”:你必须不停地奔跑,才能停留在原地。
现在,这个自然界的法则,正在数字世界里被重新演绎。
Core War:30年前的程序员对决,今天成了AI的训练场
1984年,几位计算机科学家在实验室里玩了一个疯狂的游戏——Core War。规则简单到极致:两个“战士”程序,用一种叫Redcode的微型汇编语言,在一块共享内存里厮杀。没有图形界面,没有音效,只有指令在内存中跳转、复制、破坏。谁能让对方程序崩溃,谁就赢。
听起来像极了80年代的黑客极客文化。但没人想到,30多年后,它会成为AI研究的“理想沙盒”——因为它的规则纯粹、边界清晰、胜负分明,完美模拟了“对抗性进化”的环境。
DRQ实验:让AI自己打“淘汰赛”
Sakana AI团队的突破,不是让AI写一个更强的程序,而是让AI“一代代进化”。
他们设计了名为Digital Red Queen(DRQ)的系统:每一轮,大语言模型(LLM)会生成上百个新“战士”程序,这些程序不是凭空设计,而是基于上一轮所有存活者的“基因”变异而来。然后,每个新战士都要和历史上所有曾出现过的对手——成百上千个旧程序——逐一对战。
胜者留下,败者淘汰。但关键不是赢一场,而是赢“所有场”。系统用MAP-Elites算法确保多样性——不只追求“最强”,还要保留“不同打法”。就像自然界不会只进化出一种猎豹,而是有快的、有耐力的、有伏击型的。
单轮训练的AI很“专精”,多轮训练的AI才“全能”
研究人员一开始以为,AI只要被训练去击败某个固定对手,就能变得极其高效。结果发现:确实,单轮优化的战士群体整体战斗力惊人,能碾压90%以上人类编写的经典程序。
但一拆开看,问题来了:大多数战士只能赢不到30%的对手。它们像特种兵,专攻一种战术,一旦遇到陌生打法,立刻崩溃。
而经过多轮进化、持续对抗的AI战士,却展现出惊人的“通用性”。它们不再依赖单一套路,而是能识别并应对多种攻击模式:有的会伪装成无害代码诱敌深入,有的擅长快速复制干扰内存,有的甚至能“反向追踪”对手的攻击路径,提前设伏。
它们不再只是“强”,而是“聪明”。
殊途同归:AI也懂“趋同进化”
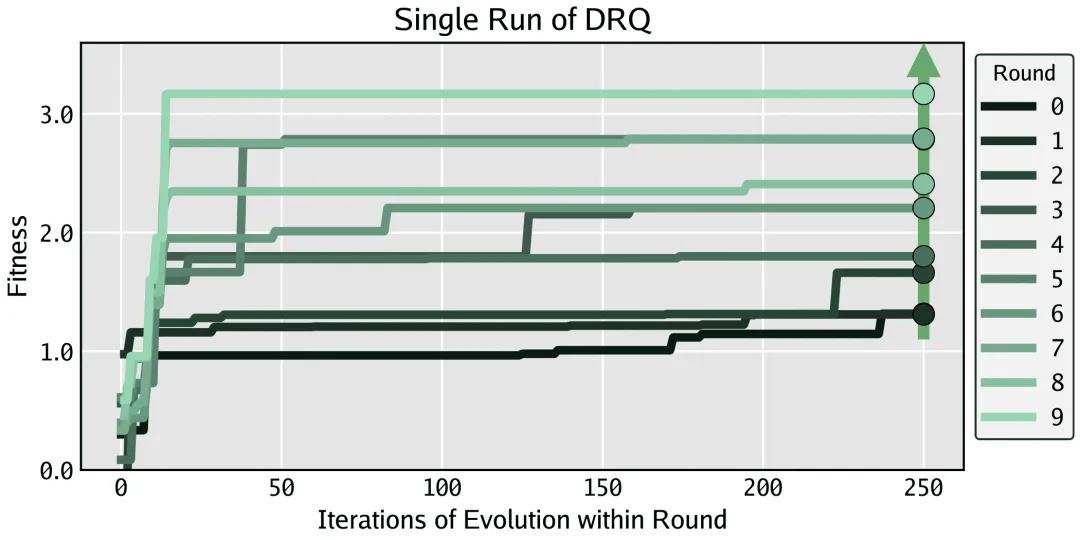
最让人震撼的,是独立运行的两组DRQ系统——它们从完全不同的初始种子出发,经过10轮进化后,竟产生了行为高度相似的战士。
它们的代码结构完全不同,变量命名、指令顺序、跳转逻辑都截然不同。但它们的“策略”却惊人一致:都懂得利用“自复制”制造干扰,都擅长“空指令陷阱”诱使对手跳入死循环,都学会了“延迟攻击”以避开早期防御。
这就像自然界中,鲨鱼和海豚,一个脊椎动物、一个哺乳动物,却都进化出了流线型身体和背鳍——不是因为它们有共同祖先,而是因为海洋给了它们同样的生存压力。
AI,也在数字海洋中,找到了属于自己的“最优解”。
不只是游戏:AI安全的未来,藏在这场对抗里
Core War不是终点,它是一面镜子。
今天,AI已深度渗透金融风控、医疗诊断、自动驾驶、政务审批——这些系统不再孤立运行,它们彼此交互、互相试探、甚至被恶意攻击者利用。一个AI模型可能被另一个AI模型“欺骗”、诱导输出错误结果,就像黑客用对抗样本让人脸识别系统认错人脸。
传统“打补丁”式安全防护,已经跟不上节奏。你封一个漏洞,对方立刻进化出新攻击方式。这,正是红皇后效应的现实映射。
DRQ实验告诉我们:真正的鲁棒性,不是靠人工预设规则,而是靠持续对抗、自我演化。未来的AI系统,或许不该是“被训练好的专家”,而应该是“能不断自我更新的生存者”。
谷歌DeepMind的AlphaDev、OpenAI的Codex,早已在代码优化中展现AI的创造力。而DRQ,是第一次让AI在“生死对决”中,自发形成复杂、稳定、通用的对抗策略——这可能是通往“自主AI安全体系”的关键一步。
下一个十年,AI将如何“进化”?
我们正站在一个转折点上。
当AI不仅能写代码,还能“思考”如何打败其他AI;当它们不再依赖人类的指令,而是通过持续对抗,自发形成防御与攻击的智慧——我们是否该重新思考:什么是AI的安全?什么是AI的智能?
也许,真正的AI文明,不是由人类设计出来的,而是由无数个AI在数字世界中,不断厮杀、学习、适应、进化……最终自然长出来的。
红皇后从不说话。她只是跑得更快。