当代码Agent越来越聪明,问题却变成了“信息太多,记不住”
你有没有遇到过这样的情况:你让AI助手帮你分析一段报错日志,它却说“信息不完整”;或者你刚问完一个复杂问题,它突然开始重复之前说过的内容——不是它“笨”,而是上下文窗口撑爆了。
随着大模型能力飞速提升,我们以为AI能“记住一切”。但现实是:上下文窗口没有无限增长,而你给它的信息——终端输出、工具返回、历史对话、MCP工具描述、甚至整份日志文件——正以指数级膨胀。结果?token爆表、噪声淹没关键信息,AI在“信息过载”中开始“失忆”。
Cursor的破局之道:别塞了,让它自己找
Cursor团队发现了一个反直觉的真相:当模型足够强大时,给它越多,反而越差。与其把所有东西塞进提示词,不如教它“怎么找”。
他们做了一个大胆的决定:把所有可能膨胀上下文的内容——日志、对话、工具描述、技能文档——全部统一变成**文件**。然后,赋予Agent读取、搜索、筛选这些文件的能力。就像一个经验丰富的工程师,不会把整本手册背下来,而是知道去哪本抽屉里翻。
这带来的改变是实打实的:token消耗直降,响应更精准,AI不再“瞎猜”,而是“有据可查”。
五大落地场景,每一项都直击开发者痛点
1. 超长工具输出?别截断,写进文件,随查随用
过去,shell命令返回5000行JSON日志?系统直接截断前500行,结果关键错误被砍掉。现在,Cursor自动把完整输出保存为./logs/tool_output_20250405.json,Agent不再“被迫总结”,而是能用tail -n 100看最新错误,用grep "500"精准定位问题。
你甚至可以手动打开文件,确认内容无误,再让AI继续分析——信息完整,掌控感拉满。
2. 摘要不是终点,历史对话随时“复活”
当你对话超过上下文限制,系统会自动生成摘要。但摘要?就像一张地图的缩略图——你看得懂方向,但找不到具体门牌号。
Cursor把完整对话记录存为./history/chat_12345.txt,摘要里只留一个引用:“详情见历史文件 #12345”。如果AI发现摘要不够,它会主动问:“我需要查看第3轮对话中提到的数据库配置吗?”——而不是凭空猜测。
这意味着:你不用再重复解释,AI也不会“忘记”你三天前提过的一个变量名。
3. Agent Skills:技能不是“内置”,而是“可安装”
以前,你得把“如何部署Docker”“怎么写K8s YAML”这些规则一股脑塞进提示词。现在,Cursor支持开放标准Agent Skills——每个技能就是一个独立文件:skills/deploy-docker.md、skills/fix-python-dep.md。
你可以自己写技能,也可以从社区下载。AI不需要记住所有技能,只需要知道“去skills/目录下,用语义搜索找‘部署’相关的”。更酷的是,技能文件里还能嵌入可执行脚本——比如一个自动修复依赖的.sh文件,AI能直接调用。
这不再是“AI助手”,而是你团队里的“可扩展智能员工”。
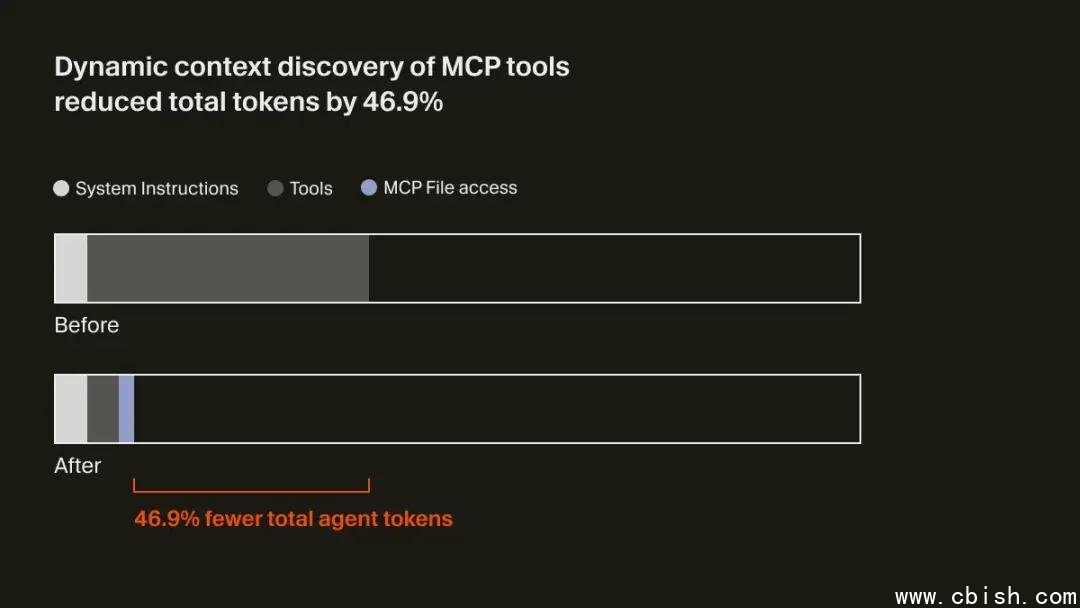
4. MCP工具:不是全量加载,而是按需唤醒
MCP(Model Control Protocol)让AI能访问生产环境、内部文档、OAuth保护的API——但每个工具的描述动辄上千词。一次加载20个工具?光描述就占掉30%上下文。
Cursor的做法是:把所有MCP工具描述同步到./mcp/tools/文件夹,提示词里只保留一个极简列表:“可用工具:auth, logs, db, ci”。真正需要时,AI才去查db.json里具体怎么调用。
实测效果惊人:在涉及MCP的场景中,**token消耗降低46.9%**。更聪明的是,AI还能检测工具文件的“最后修改时间”或“认证状态”,一旦发现token过期,它会主动提醒你:“MCP工具‘prod-logs’已失效,请重新登录。”——再也不用等你发现报错才反应过来。
5. 终端历史,自动变成AI的“记忆库”
以前:你跑完一个命令,复制输出,粘贴给AI,说“帮我看看这个错误”。现在:Cursor自动把集成终端的每一次输出,保存为./terminal/session_001.log。
你再也不用复制粘贴。直接问:“我昨天下午3点跑的部署脚本,为什么报错403?”——AI立刻去翻session_001.log,定位到那条命令,分析输出,甚至对比前后几次执行差异。
对运维、后端、数据工程师来说,这简直是“AI版历史命令回溯”——尤其在跑长时间任务、监控服务日志时,价值翻倍。
为什么是“文件”?因为它是AI时代的“Unix哲学”
有人问:为什么不设计一套全新的API或数据库?Cursor的回答很务实:
“在AI快速演进的今天,我们不需要一个‘未来五年不会过时’的复杂系统。我们需要一个‘现在能用、十年后还能读’的原语。”
文件,简单、可读、可版本控制、跨平台、支持任意工具读写。你用VS Code能看,用grep能搜,用git能管,用Python能解析——它不依赖任何AI框架,不绑定任何厂商。今天你用Cursor,明天你换工具,文件还在。
这就像当年Unix用“一切皆文件”统一了设备、进程、网络——现在,Cursor用“一切皆文件”统一了AI的上下文。
这不是升级,是范式转移
过去一年,大家拼模型参数、拼推理速度、拼多模态能力。但Cursor的这套机制,悄悄把竞争焦点从“模型有多强”,转向了“系统有多聪明”。
真正的下一代AI开发助手,不是那个能背下整本文档的“记忆大师”,而是那个知道“在哪找、怎么查、何时问”的**高效协作者**。
这套动态上下文系统,将在未来几周内向所有Cursor用户逐步开放。如果你是重度使用AI编程的开发者——现在,你该重新思考:你给AI的,是“信息”,还是“线索”?
答案,藏在那个你从未注意过的./logs/文件夹里。