当所有人都在拼参数,他们选择让AI学会“思考”
当行业还在为千亿、万亿参数的模型狂欢时,MiroMind团队却问了一个更尖锐的问题:如果一个AI能背下整座图书馆,但它永远分不清真假信息,那它真的“聪明”吗?
答案是否定的。真正的智能,不是记住多少,而是知道什么时候该停下、去查证、去修正。
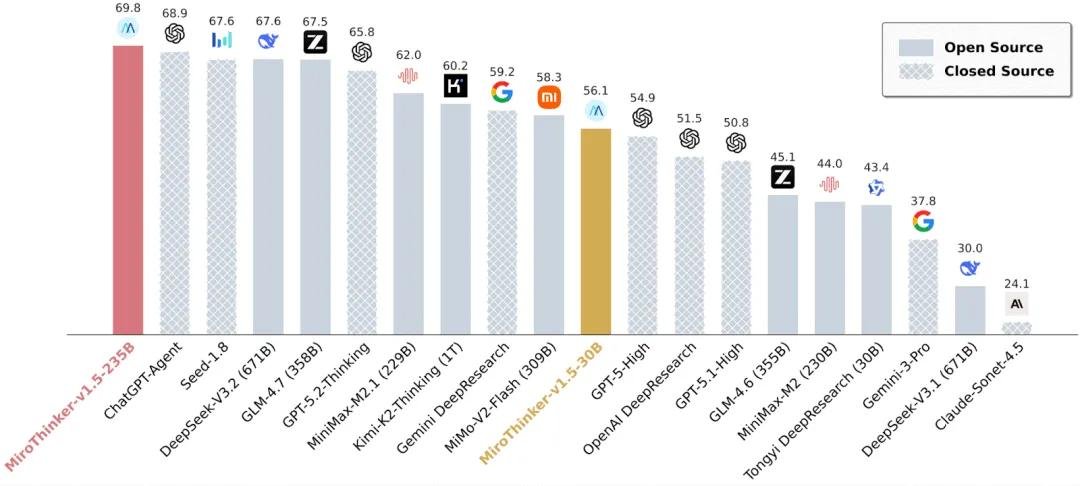
30B参数,干掉30倍大的模型
MiroThinker-v1.5-30B,一个只有300亿参数的模型,在多个权威搜索代理基准测试中,性能与千亿甚至万亿级模型持平,甚至超越。
在中文场景最具挑战性的BrowseComp-ZH测试中,它击败了参数量是其30倍的Kimi-K2-Thinking——推理成本却只有后者的1/20。这不是小幅度优化,而是一次结构性突破。
更惊人的是,它的235B版本在多个国际公开评测中稳居全球第一梯队,成为少数能在真实搜索任务中稳定调用外部工具、动态修正答案的模型之一。
它不是“答题机器”,是“科研助手”
传统大模型像一个背了十年课本的考生:题目一出,立刻翻记忆,选最“可能”的答案。哪怕没学过,也能编出一套逻辑严密的假话——这就是我们常说的“幻觉”。
MiroThinker 1.5不一样。它被训练成一个真正的“科学家”:
- 面对未知问题,它不急着回答,而是先提出假设;
- 然后主动联网查询最新资料,不是靠记忆,而是调用实时信息源;
- 发现矛盾?立刻反向验证,寻找反例;
- 证据不足?暂停判断,等待更多数据;
- 直到多个独立信源交叉印证,才给出最终结论。
这不再是“生成文本”,而是模拟人类科学推理的完整闭环。
为什么它能“小而强”?因为训练方式彻底变了
传统模型训练,是“上帝视角”:你直接告诉它正确答案,它只需要学会复述。
MiroMind的团队做了三件颠覆性的事:
- 惩罚“捷径思维”:哪怕答案看起来很合理,只要没经过外部验证,直接扣分。
- 奖励“拆解+查询”:模型每分解一个复杂问题为可验证子任务,并成功调用外部数据,就获得高奖励。
- 引入“时序敏感训练沙盒”:这是最硬核的创新。模型在训练时,只能访问“问题发生时间点之前”的信息。比如问“2024年7月特斯拉股价是多少?”,它不能看到2024年8月的财报——必须像真实用户一样,在信息不完整、有延迟、有噪音的条件下做判断。
这意味着,MiroThinker学到的不是“标准答案”,而是如何在真实世界中做决策。
这不是AI的进化,是认知方式的革命
过去十年,AI的进步靠的是“更大、更多、更快”——更大的模型、更多的数据、更快的算力。
MiroThinker 1.5证明:这条路已经触顶。真正的下一个拐点,是让AI从“记忆者”变成“探究者”。
它不追求“无所不知”,而是追求“知之为知之,不知而能查”。
在信息爆炸、假新闻泛滥的时代,我们更需要的不是能说会道的AI,而是能帮你辨别真伪、拒绝臆测、坚持证据的智能伙伴。
现在,你可以亲自验证
无需注册,无需等待——直接体验MiroThinker 1.5的“科学家模式”:
输入一个你曾被AI“骗过”的问题——比如“2025年iPhone 17有哪些新功能?”或“最近有哪位诺贝尔奖得主发表了争议性言论?”——看看它会不会直接编答案,还是停下来,查证,再回答。
这,才是AI该有的样子。