英伟达“费曼”GPU或将引入格罗克LPU:AI推理之战正式升级
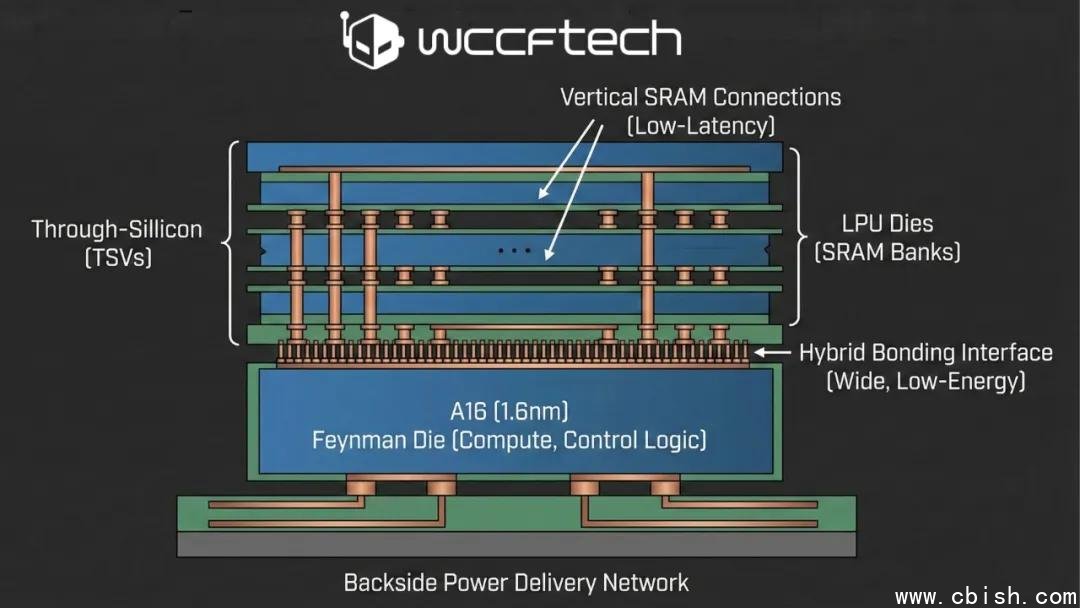
据多位芯片行业资深人士透露,英伟达正计划在2028年前后发布的“费曼”(Feynman)架构GPU中,首次集成来自初创公司格罗克(Groq)的LPU(Language Processing Unit,语言处理单元)技术。这一举措并非简单的技术整合,而是一场针对AI推理性能的体系级重构——英伟达将不再试图把大容量SRAM直接嵌入GPU核心,而是选择以3D堆叠方式,将独立的LPU芯片“嫁接”在主计算芯片之上。

为何不把SRAM塞进GPU?成本与效率的现实博弈
长期以来,GPU通过集成大容量缓存来提升数据吞吐,但随着制程进入1.6nm甚至更先进节点,SRAM的单位面积成本飙升已成行业共识。根据TSMC内部数据,1.6nm节点下,SRAM单元的制造成本是逻辑电路的3倍以上,且良率下降明显。与其在昂贵的先进制程上“浪费”硅面积,不如把SRAM迁移到成本更低、工艺更成熟的2.5D/3D封装层。
格罗克的LPU正是为此而生——它专为LLM(大语言模型)推理优化,采用固定流水线架构,内置高达100GB+的片上SRAM,延迟低至纳秒级,单芯片即可支撑千亿参数模型的实时推理。而英伟达的主芯片,将专注张量计算、并行调度等核心任务,双方各司其职,形成“计算+缓存”的黄金搭档。
台积电SoIC技术成关键:垂直互连打破“内存墙”
实现这一架构的核心,是台积电(TSMC)的SoIC(System on Integrated Chips)混合键合技术。该技术可实现每平方毫米超10,000个微凸块(microbumps),互连密度是传统CoWoS封装的5倍以上,同时支持背面供电(BPD, Backside Power Delivery)。
在费曼GPU中,主芯片正面将通过SoIC直接与LPU芯片键合,形成超低延迟、超高带宽的垂直通道。据业内模拟数据显示,这种架构可将AI推理的内存访问延迟降低40%以上,每比特能耗下降达35%,对云服务商而言,意味着单卡可支撑更多并发请求,TCO(总拥有成本)显著下降。
热设计与软件生态:英伟达面临的双重挑战
然而,这条路并非坦途。LPU芯片与GPU主芯片的3D堆叠,将使芯片整体热密度逼近极限。据AnandTech分析,若LPU持续满载运行,局部热流密度可能超过200W/cm?,远超当前液冷散热系统的安全阈值。这意味着,英伟达必须重新设计散热方案——可能引入微流道冷却、相变材料或定制化均热板,成本或将增加15%-20%。
更大的挑战来自软件生态。CUDA作为全球AI开发的“操作系统”,依赖的是灵活的线程调度与动态内存管理。而LPU的执行模型高度刚性:指令顺序固定、内存访问预分配、无分支预测。这与CUDA的“异构并行”哲学背道而驰。
如何在不颠覆现有开发者习惯的前提下,引入LPU的高效推理路径?英伟达可能推出“CUDA-LPU”扩展接口,允许开发者通过新API(如cudaLaunchLPUKernel())显式调用LPU资源,同时保留传统GPU路径作为兜底。NVIDIA Research已在2024年IEEE Hot Chips会议上披露了“混合执行模型”原型,暗示其已在内部推进相关编译器改造。
不只是升级,而是战略转向:推理,成为AI新战场
过去十年,AI竞赛的焦点是训练——谁的GPU算力更强,谁就能训练更大的模型。但如今,市场重心已悄然转移。据Counterpoint Research最新报告,2025年全球AI推理芯片市场规模将首次超越训练市场,达到780亿美元,年复合增长率达42%。
谷歌TPU、亚马逊Trainium、微软Maia、以及格罗克LPU,都在围绕“推理效率”展开围猎。而英伟达,正面临一个关键抉择:是继续用GPU“硬扛”推理,还是主动拥抱专用架构,打造“训练用Hopper/Blackwell,推理用Feynman+LPU”的双轨体系?
业内普遍认为,后者才是长远之计。若费曼GPU真能实现LPU堆叠,这不仅是封装技术的突破,更是英伟达从“通用加速器”向“推理专用平台”转型的里程碑。未来,AI云服务的竞价核心,可能不再是FLOPS,而是“每秒推理token数”与“每美元推理成本”。
结语:2028年,谁掌握推理,谁就定义AI未来
尽管费曼GPU是否搭载LPU仍存变数,但趋势已不可逆。英伟达正在悄悄构建一个“推理优先”的新生态:从硬件架构、封装技术到软件接口,都在为“低延迟、高吞吐、低成本”的推理场景铺路。
对开发者而言,这意味着未来训练和推理将彻底分离;对云厂商而言,这意味着算力采购将从“买算力”转向“买推理效率”;对投资者而言,这或许是AI硬件赛道下一个十年的胜负手。
2028年,当费曼GPU揭开面纱,我们或许会看到:一个不再只靠CUDA统治世界的英伟达——但更强大,更专注,也更不可替代。