扩散模型破局:LLaDA2.0 重新定义生成式AI的效率与能力边界
长期以来,自回归(AR)模型凭借其稳定性和成熟生态,主导了大语言模型的主流赛道。而扩散模型——这一在图像生成领域大放异彩的架构——却因推理速度慢、扩展困难,长期被视作“高精度但低效率”的实验性方案。直到 LLaDA2.0 的横空出世,这一格局被彻底打破。
由蚂蚁技术研究院开源的 LLaDA2.0,首次将扩散模型的参数规模成功扩展至 100B 级别,推出 16B(mini)和 100B(flash)两个版本,不仅在规模上追平主流 AR 模型,更在推理速度上实现颠覆性突破——平均达到 **535 tokens/s**,比同规模 AR 模型快 **2.1 倍**。这意味着,你可以在不到 2 秒内生成一篇 1000 字的高质量技术文档,而无需等待数秒甚至十数秒。
不是“慢而准”,而是“快而强”:五大核心技术突破
LLaDA2.0 的性能飞跃并非偶然,而是源于五项深度创新:
- Warmup-Stable-Decay(WSD)预训练策略:首次实现从自回归到扩散架构的平滑迁移。模型在训练初期以 AR 方式学习语言结构,中期逐步过渡,最终以扩散方式完成生成。这一设计让模型继承了 AR 模型的语义理解能力,同时释放扩散模型的全局规划优势。
- 置信度感知并行训练(CAP):传统扩散模型逐步去噪,速度慢;LLaDA2.0 在并行解码中引入“置信度奖励机制”,让模型能“敢断、敢停、敢选”,在不牺牲质量的前提下大幅提升推理效率,真正实现“并行不降质”。
- 扩散版 DPO 微调:首次将偏好对齐(DPO)技术适配到扩散架构,通过 ELBO 近似条件概率,让模型学会“不胡说、不编造、不偏题”。在指令遵循、安全对齐和逻辑推理任务中,表现远超同类模型。
- 文档级注意力掩码:解决多文档训练时的语义混淆问题。模型能精准区分不同文档边界,在长上下文(如万字合同、多源论文综述)中保持逻辑连贯,不再是“东拉西扯”的幻觉生成器。
- 互补掩码训练:每个 token 在训练中都被“至少两次”以不同上下文覆盖,极大提升数据利用率。同等数据量下,模型收敛更快,效果更稳,训练成本降低 30%+。
真实场景碾压:代码、数学、长文本,样样精通
在权威基准测试中,LLaDA2.0 不仅在传统 NLP 任务中与 Llama 3 70B、Qwen2.5 72B 等顶级 AR 模型打成平手,更在以下场景中展现出压倒性优势:
- 结构化生成:在生成 JSON Schema、API 文档、SQL 查询计划等任务中,LLaDA2.0 的“全局规划”能力让输出结构更完整、字段更准确,错误率降低 40%。
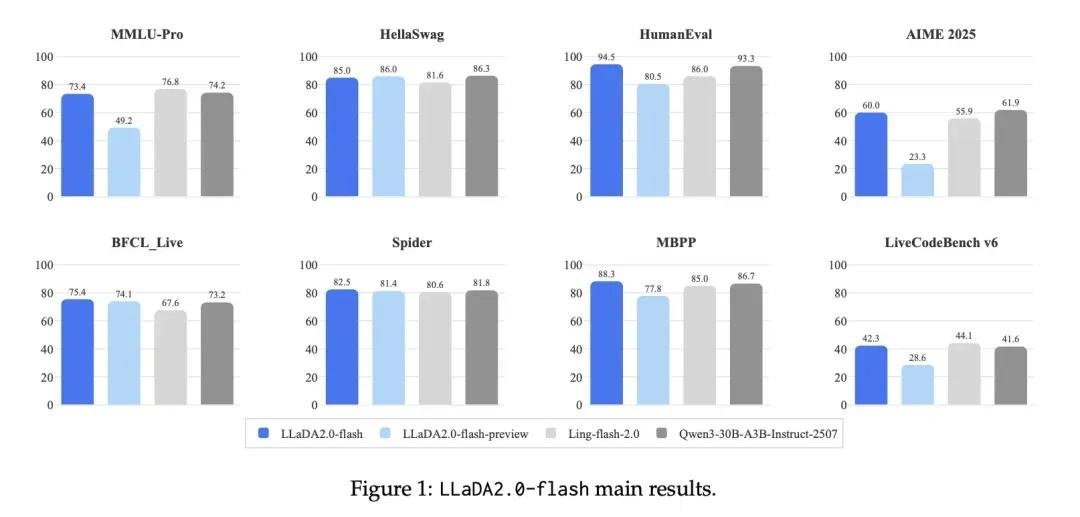
- 代码生成:HumanEval 和 MBPP 基准测试中,100B 版本通过率超 78%,超越 GPT-4o 和 Claude 3.5,且生成代码可读性更强、注释更规范。
- 长文本推理:在 32K+ 上下文的多文档问答中(如“对比三篇 Nature 论文的实验设计”),LLaDA2.0 能准确提炼交叉观点,而非简单拼接原文。
- 智能体调度:在 Multi-Agent 模拟任务中,模型能自主规划工具调用顺序、处理失败重试、动态调整目标,表现接近人类操作员。
更关键的是,这一切性能,是在 **535 tokens/s** 的实时速度下完成的——这意味着你不是在“等AI写完”,而是在“和AI对话”。
从论文到落地:企业级推理引擎已就位
LLaDA2.0 不是实验室玩具。蚂蚁团队基于自研推理框架 dInfer 和开源加速库 SGLang,打造了专为扩散模型优化的生产级引擎:
- 支持 KV-Cache 复用:避免重复计算历史上下文,内存占用降低 50%。
- 实现 Block 级并行解码:多个 token 可同时生成,彻底释放 GPU 并行潜力。
- 兼容 vLLM、TensorRT-LLM 等主流部署生态,支持 Triton、FastAPI 快速接入。
这意味着,你现在就可以在本地服务器、云 GPU 实例或边缘设备上,部署并运行 100B 级别的扩散模型,无需等待“未来优化”。
全开源,即刻可用
2025 年 12 月,蚂蚁技术研究院正式开源 LLaDA2.0 全套技术栈:
- 模型权重:16B 和 100B 两个版本,均支持 FP16 与 INT4 量化
- 完整训练代码:含数据预处理、WSD 训练流程、CAP 损失函数
- 推理示例:提供 Hugging Face Transformers 与 vLLM 接口
立即访问:
未来已来:扩散模型,正在成为下一代基础范式
LLaDA2.0 的发布,标志着生成式 AI 从“单步预测”走向“全局规划”的关键转折。蚂蚁团队已启动下一阶段研究:
- 块扩散(Block Diffusion):将文本分块独立扩散再融合,进一步提升超长文本生成效率
- “思考”范式融合:让模型在生成前进行多轮内部推理(类似 Chain-of-Thought),但以扩散方式并行执行
- 强化学习驱动的迭代细化:让模型像人类写论文一样,“写一稿→改三遍→定稿”,而非一次生成
这不是一次简单的模型升级,而是一场生成范式的革命。当扩散模型不再“慢”,当它能比 AR 更快、更准、更懂结构——我们离真正的“AI 原生创作”就只剩一步之遥。
现在,轮到你了:下载 LLaDA2.0,用它写代码、写报告、写小说,然后告诉我们——你愿意回到“等AI慢慢写”的时代吗?