CUDA Tile:英伟达十年来最颠覆性的GPU编程变革
2024年底,英伟达在CUDA 13.1中正式推出CUDA Tile——被官方称为“自2006年CUDA问世以来最大规模的一次架构级进化”。这不是一次简单的API升级,而是一场从底层编程范式到编译器生态的全面重构。它的目标直指GPU编程的核心痛点:让开发者不再为线程调度、内存层级、架构差异而头疼,像写NumPy一样写高性能GPU代码。
为什么我们需要CUDA Tile?
过去十几年,CUDA靠SIMT(单指令多线程)模型统治了GPU计算。但随着AI、科学计算和实时渲染对算力需求爆炸式增长,硬件早已不是当年的“并行加速器”——Tensor Core、TMA(Tensor Memory Accelerator)、Hopper架构的跨片存取引擎、FP8支持……每一项新特性都让代码复杂度呈指数上升。
一个现实问题是:你为A100写的高效矩阵乘法,到了H100上可能需要重写;为Ada Lovelace优化的显存访问模式,在Blackwell上可能反而变慢。开发者被迫成为“硬件工程师”,而不再是算法实现者。
更讽刺的是:我们用PyTorch、JAX写一行x @ y,背后是成千上万行手工调优的CUDA内核。这种“高层抽象 vs 底层复杂”的割裂,正在成为AI创新的瓶颈。
CUDA Tile 是什么?一句话说清
CUDA Tile 的核心思想是:用“数据块”(Tile)代替“线程”作为编程单位。你不再关心“我该启动多少个block、每个block多少线程、怎么用shared memory缓存”,而是告诉系统:
- “这个张量分成 16x16 的块”
- “对每个块做矩阵乘加”
- “结果写回全局内存”
剩下的——如何映射到Tensor Core、如何用TMA预取数据、如何在不同架构上自动调整块大小、如何避免bank conflict——全部交给编译器和运行时自动处理。
这就像你在Python里写np.dot(A, B),不用管底层是调用了BLAS、SSE指令还是AVX512。CUDA Tile 让GPU编程终于进入了“声明式时代”。
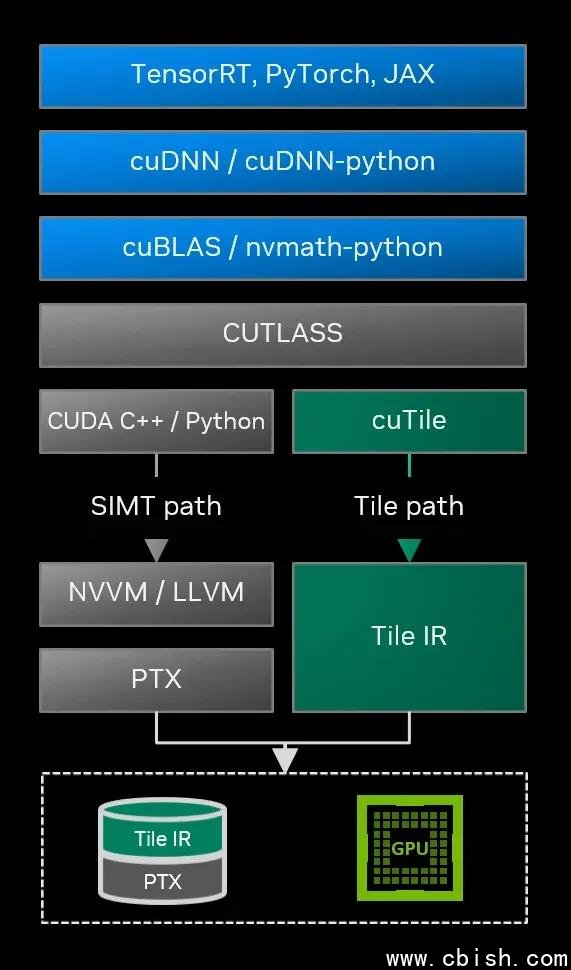
背后的技术:Tile IR,CUDA的“新PTX”
CUDA Tile 的真正革命性,在于它引入了一套全新的中间表示——CUDA Tile IR(Intermediate Representation)。
如果说PTX是SIMT时代的“GPU汇编语言”,那么Tile IR就是为张量操作量身打造的“张量汇编”。它不描述线程,而是描述:
- 张量的维度与布局(stride, shape)
- 块的读写模式(tile load, tile store)
- 计算指令(tile.mma, tile.fma)
- 内存同步与跨线程块通信
这意味着:未来所有AI框架(PyTorch、JAX、TensorRT)、编译器(Triton、MLIR)、算子库(cuDNN、cuBLAS)都可以基于Tile IR构建,不再需要为每个新架构重写底层代码。
更重要的是,Tile IR与PTX完全兼容。你可以在同一个程序中混合使用两者——需要极致控制时用PTX,追求生产力时用Tile。这不是取代,而是进化。
开发者怎么用?两种路径,总有一款适合你
英伟达没有搞“一刀切”,而是提供了清晰的双轨路径:
1. 普通开发者:用 cuTile Python —— 像写 NumPy 一样写GPU
这是绝大多数AI工程师和科研人员的入口。英伟达已开源cuTile Python库,语法极度简洁:
无需写任何__global__函数,无需管理shared memory,甚至不需要知道你用的是H100还是L40S——性能自动适配。官方已提供与PyTorch无缝集成的示例,训练/推理代码几乎零修改即可提速20%~40%。
目前cuTile已支持主流AI模型的算子(GEMM、Softmax、LayerNorm、Attention),未来将覆盖更多稀疏计算和动态形状场景。
2. 底层开发者:直接操作 Tile IR —— 构建下一代AI编译器
如果你是Triton、MLIR、ONNX Runtime或自研编译器的开发者,Tile IR是你必须掌握的新语言。它提供了完整的语法规范、语义定义和优化原语,支持:
- 自定义tile布局(非方块、非对称)
- 跨层级内存亲和性声明
- 混合精度计算的精确控制
- 与PTX混合编码(用于关键路径优化)
英伟达已开放完整的Tile IR官方文档,并提供LLVM后端支持。这意味着,未来你写的Triton算子,可能直接编译成Tile IR,跑在所有新一代NVIDIA GPU上,无需重新优化。
这不是未来,是现在:谁已经在用了?
截至2025年初,以下项目已接入CUDA Tile:
- PyTorch 2.5+:部分torch.compile后端启用cuTile,FP16 GEMM性能提升最高达38%
- TensorRT-LLM 1.0:推理引擎全面采用Tile IR,LLM吞吐量提升25%+(H100上实测)
- Apache TVM:已支持Tile IR后端,成为首个支持多架构统一算子生成的开源编译器
- Meta Llama 3:部分注意力模块在训练中使用cuTile,显存占用降低17%
据英伟达内部透露,未来所有AI芯片(如B200、Blackwell Ultra)将优先支持Tile IR,PTX将逐步退居“兼容模式”。
总结:GPU编程的“iPhone时刻”来了
CUDA Tile的意义,不在于它多“快”,而在于它让GPU编程从“专家专属”走向“大众可用”。
过去,你要懂寄存器分配、warp divergence、memory coalescing,才能写出高效代码;现在,你只需要知道“我要算什么”。
这就像从手动挡车换到自动驾驶——你依然能踩油门,但不用再管换挡时机。
对于AI开发者而言,这意味着:
- 模型训练更快、更稳定
- 算法实验周期缩短
- 不再为新卡“重新调参”
- 开源生态将爆发式增长
如果你还在用CUDA 12写线程布局,现在是时候看看cuTile了——不是为了跟风,而是为了不被淘汰。
英伟达的野心,是让CUDA成为“AI时代的C语言”——而CUDA Tile,就是它迈出的最关键的一步。