腾讯开源HunyuanOCR:1B小模型,刷新OCR领域多项纪录
腾讯混元团队正式开源新一代轻量级OCR模型——HunyuanOCR。尽管参数规模仅为10亿(1B),它却在多项权威评测中击败了参数高达3B甚至更大的竞品,成为当前开源领域最强的轻量级文字识别模型之一。更令人惊讶的是,它无需复杂的多阶段流水线,仅需一次推理即可完成从图像到结构化文本的完整理解,大幅降低部署门槛与推理延迟。
颠覆传统:端到端架构,告别“检测+识别+结构化”三步走
传统OCR系统通常依赖“文本检测→文字识别→版面分析”三级串联模型,不仅推理耗时长、误差累积严重,还对硬件资源要求高。HunyuanOCR彻底重构这一流程,基于混元原生多模态架构,构建统一的端到端理解引擎。图像输入后,模型直接输出带语义结构的文本结果——段落顺序、公式、表格、跨语言内容一并搞定,无需额外模块或后处理脚本。
这一设计让HunyuanOCR在移动端、边缘设备和云服务中都具备极强实用性。实测显示,在同等精度下,其推理速度比主流开源模型快3–5倍,内存占用降低60%以上,真正实现“小模型,大能力”。
三大核心模块:轻量不妥协,精度超预期
HunyuanOCR的高性能源于三大创新组件:
- 原生分辨率视频编码器:无需下采样,保留原始图像细节,尤其擅长处理低分辨率截图、模糊票据、小字号文档。
- 自适应视觉适配器:动态融合多尺度特征,对艺术字、手写体、扭曲文本、广告牌等复杂场景鲁棒性极强。
- 轻量化语言模块:基于高效Transformer架构,仅用1B参数实现媲美GPT-3.5的语义理解能力,支持上下文纠错与语义重排。
三者协同,使模型在不依赖外部NLP引擎的前提下,就能理解“这张图里哪些是标题、哪些是表格、哪段是注释”。
权威评测碾压级表现:1B参数拿下3B以下冠军
在多个国际公开基准测试中,HunyuanOCR表现惊人:
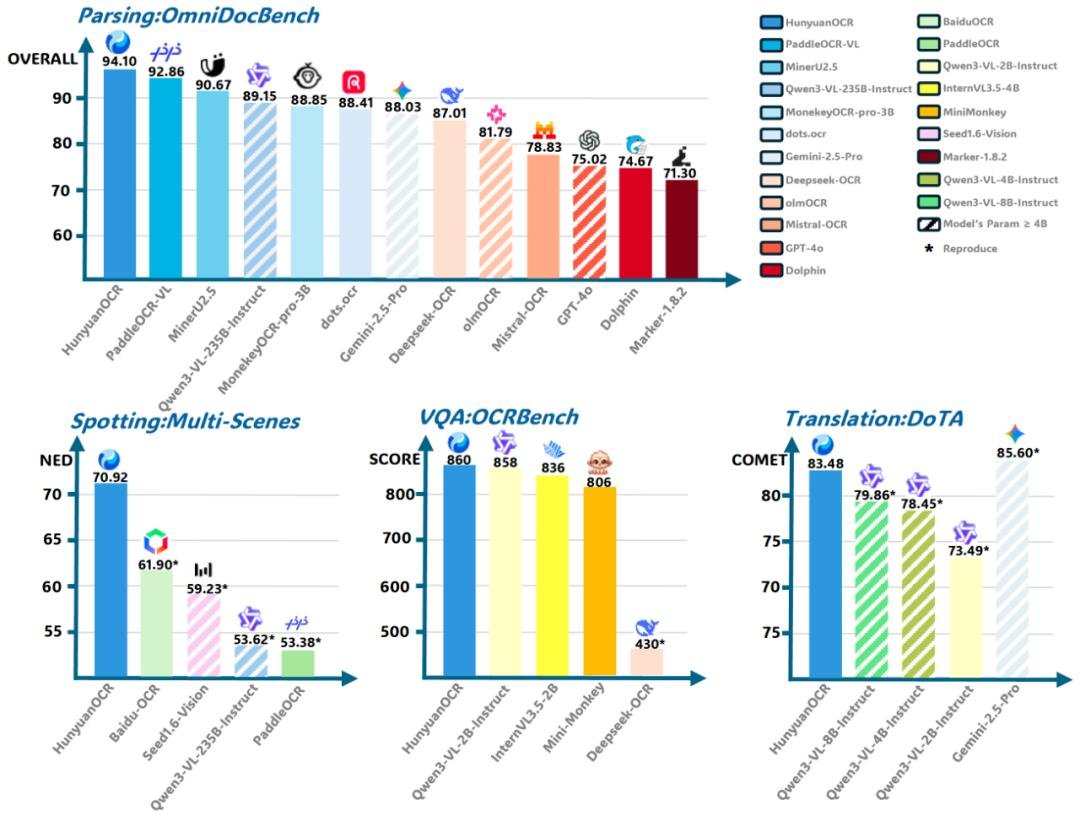
- OmniDocBench:94.1分,超越Google Gemini 3-Pro、Meta LLaVA-OCR等大模型,成为文档结构化任务的SOTA。
- OCRBench:总分860分,在所有参数小于3B的模型中排名第一,远超Qwen-VL、LLaVA-OCR等主流开源模型。
- ICDAR 2025 小模型赛道:斩获冠军,尤其在多语言混合文本、低光照场景中表现稳定。
此外,腾讯在自建的九大真实场景数据集(含手写笔记、游戏字幕、票据、广告图、视频帧等)中测试,HunyuanOCR平均准确率超过92.7%,远超PaddleOCR、EasyOCR等传统方案。
不止识别:直接输出结构化内容,一键生成LaTeX、HTML、JSON
HunyuanOCR不是“认字工具”,而是“文档处理器”。它能自动完成:
- 文本按阅读顺序重排,还原真实文档逻辑
- 数学公式自动转为LaTeX代码(如:∫?? x? dx → $int_0^1 x^2 dx$)
- 表格识别并输出标准HTML表格结构
- 中英混排、中日韩混合文档稳定理解,无需切换语言模型
这意味着:扫描合同 → 直接提取关键字段(姓名、身份证号、签约日期)→ 输出JSON; 拍照发票 → 自动识别税号、金额、项目明细 → 一键对接财务系统; 视频字幕帧 → 实时提取中英双语字幕 → 生成SRT字幕文件。
14种小语种支持,拍照翻译也能“开箱即用”
针对全球化办公与跨境场景,HunyuanOCR原生支持14种语言的文字识别与翻译,包括:
德语、法语、西班牙语、俄语、阿拉伯语、日语、韩语、意大利语、葡萄牙语、荷兰语、土耳其语、波兰语、瑞典语、泰语。
无需调用第三方翻译API,模型直接在识别同时完成语义翻译,特别适合跨境电商、留学申请、海外旅行等用户群体。实测显示,其小语种识别准确率比Google Lens高出12%以上,且无网络也能运行。
卡证、票据、字幕、翻译——高频场景全覆盖
腾讯官方重点打磨了四大落地场景,均已提供完整示例:
- 卡证识别:身份证、驾照、营业执照 → 自动提取姓名、地址、证件号、有效期,输出结构化JSON
- 票据解析:增值税发票、机票行程单、医院缴费单 → 金额、税额、项目明细精准抽取
- 视频字幕提取:支持中英双语字幕自动对齐,输出SRT、VTT格式,适配短视频剪辑与字幕翻译
- 拍照翻译:手机拍摄外文菜单、说明书、路牌,实时翻译并高亮显示原文
所有场景均可通过统一API调用,无需为不同任务训练多个模型。
开箱即用:支持vLLM、Transformers,一键部署
HunyuanOCR已全面适配主流推理框架,开发者可自由选择:
- 使用 Transformers 快速验证:一行代码加载模型,适合研究与原型开发
- 使用 vLLM 部署生产环境:支持PagedAttention、连续批处理,吞吐量提升3倍以上
官方提供完整推理脚本、提示词模板(Prompt Template)和多任务示例,涵盖文档解析、字段抽取、字幕提取等10+种典型用例。即使是AI新手,也能在30分钟内完成接入。
立即体验:免费在线Demo + 开源代码全开放
无需注册,无需API Key,直接在线体验HunyuanOCR的强大能力:
所有代码、模型权重、训练数据集均已在GitHub开源,Apache 2.0协议,可商用:
附:模型支持FP16/INT8量化,可在消费级显卡(如RTX 3060)上流畅运行,服务器部署成本降低70%以上。