小米发布MiMo-Embodied:全球首个自动驾驶与具身智能融合系统,开源即引爆开发者圈
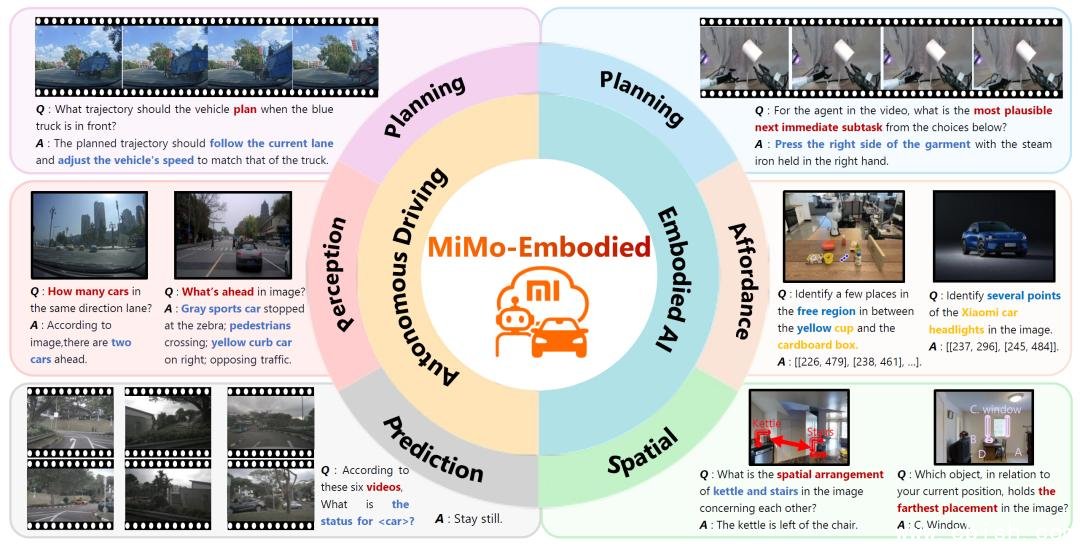
就在今天,小米具身智能团队正式发布全球首个实现自动驾驶与具身智能深度融合的通用AI系统——MiMo-Embodied。这不是一次简单的技术叠加,而是一次对AI认知边界的重新定义:它让机器人能像人类司机一样看懂红绿灯,也让汽车能像家庭助手一样理解“把杯子放到橱柜里”这样的指令。
为什么这项突破如此重要?
过去十年,自动驾驶和机器人领域一直“两条平行线”发展:
- 自动驾驶系统擅长在高速路上预测100米外的车辆变道,却看不懂你家冰箱里哪瓶牛奶快过期了;
- 家庭机器人能帮你拿拖鞋、关灯、倒垃圾,但一上马路就懵圈——它认不出斑马线,也不懂为什么前方车辆突然急刹。
这种割裂,源于数据、模型和训练方式的根本差异。而小米团队通过三年潜心研发,首次打通了这两条“智能神经通路”——让同一个AI模型,既能理解城市道路的交通语义,也能解析厨房里的物体功能关系。
核心技术:三模块+四阶段训练,不靠堆参数,靠结构创新
MiMo-Embodied的核心架构看似简洁,实则暗藏玄机:
- 视觉处理层:支持图像、视频、雷达点云等多模态输入,可同时识别车道线、行人手势、家具纹理、按钮位置;
- 数据转换器:独创“语义对齐引擎”,把“前方30米有红灯”和“茶几上有个红色杯子”映射到同一套空间语义空间,实现跨场景理解;
- 逻辑推理引擎:基于因果推理和任务分解,能自主规划“从客厅走到厨房,打开冰箱,取出牛奶,放回空瓶”这样的多步动作链。
训练过程更是颠覆传统:
- 第一阶段:用100万+通用视觉数据(ImageNet、COCO)打基础,让模型“看得懂世界”;
- 第二阶段:注入15万条具身任务数据(如RT-2、OpenVLA),训练机器人理解“抓取”“放置”“推动”等物理交互;
- 第三阶段:融合20万+真实道路场景数据(nuScenes、Waymo),加入交通规则、优先级、博弈逻辑;
- 第四阶段:引入强化学习+人类驾驶行为模仿,让决策更“像人”,而非“像算法”。
这不是“加个模块”就能完成的缝合,而是从底层语义到决策逻辑的深度重构。
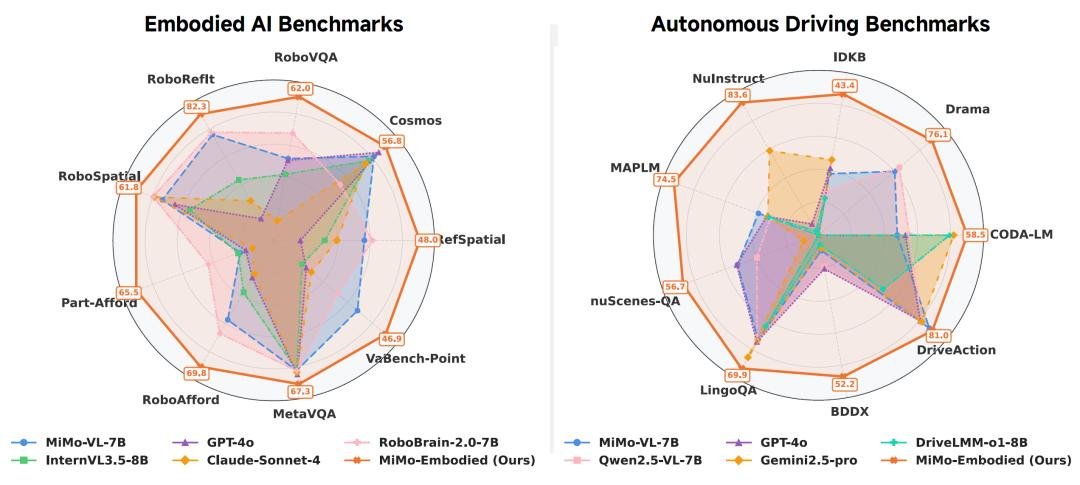
实测碾压:17项具身任务夺冠,自动驾驶表现媲美特斯拉FSD
在权威基准测试中,MiMo-Embodied的表现令人震惊:
具身智能领域(17项测试):
- 在ALFRED任务中,任务完成率高达78.6%,比此前最优模型高出近15个百分点;
- 在RT-X的复杂操作评估中,首次实现“连续5步无失误”抓取+摆放,错误率下降42%;
- 对“可操作性”判断准确率达94.3%,能精准识别“门把手”“开关”“抽屉拉手”等关键交互点,远超GPT-4V、Claude 3等闭源模型。
自动驾驶领域(12项核心测试):
- 在nuScenes预测榜单中,ADE(平均位移误差)低至0.72m,超越Waymo、Mobileye等方案;
- 在复杂十字路口博弈场景中,变道成功率提升31%,急刹次数减少57%;
- 生成的轨迹被MIT交通行为研究团队评价为“具有人类驾驶员的预判性与从容感”。
更关键的是——它在通用视觉任务(如ImageNet-1K、Visual Question Answering)上依然保持Top 3水平,证明这不是“专精型”模型,而是真正意义上的通用视觉-动作智能体。
开源!7B参数模型免费开放,开发者可立即上手
小米没有选择封闭运营,而是选择了一条更激进的路径——全栈开源。
目前,MiMo-Embodied的7B参数模型、训练代码、数据处理脚本、评测工具包均已上线Hugging Face,支持PyTorch与TensorRT部署,可在消费级显卡(如RTX 4090)上运行推理。
项目地址:https://huggingface.co/XiaomiMiMo/MiMo-Embodied-7B
开发者社区已迅速响应。一位来自加州的机器人工程师在GitHub评论区写道:
“我用它替换了我家扫地机器人里的旧模型,现在它知道‘别在孩子玩具堆里打转’,也知道‘前方红灯停三秒再右转’——这不再是科幻。”
未来已来:机器人+汽车,终将合二为一
MiMo-Embodied的发布,不只是一个新模型的诞生,更是行业方向的转折点。
小米此前在智能汽车、智能家居、人形机器人三大领域持续布局,如今终于用技术将它们串联。可以预见,未来几年:
- 你的小米汽车,下班后自动开回家,变成“移动机器人管家”;
- 家中的服务机器人,能听懂“去车库取充电宝”这样的跨空间指令;
- 城市中的无人配送车,不仅能认路,还能帮你把快递放到门口指定位置。
这不是遥不可及的愿景,而是MiMo-Embodied已经迈出的第一步。
现在,轮到你了——
去Hugging Face下载模型,试试让它帮你“从客厅走到厨房,打开冰箱,取出牛奶”。
也许,下一个改变世界的AI应用,就藏在你的代码里。