Grok 4.1 正式上线:更懂你、更可靠、真正像个人类助手
今天,Grok 正式发布全新版本 Grok 4.1,全面登陆 grok.com、????(原 Twitter)App 以及 iOS 和 Android 移动端。这不是一次简单的参数升级,而是一次从内到外的“人性化重构”——它不再只是回答问题的工具,而是开始学会倾听、共情、甚至在你犹豫时主动追问:“你确定要这个答案吗?”
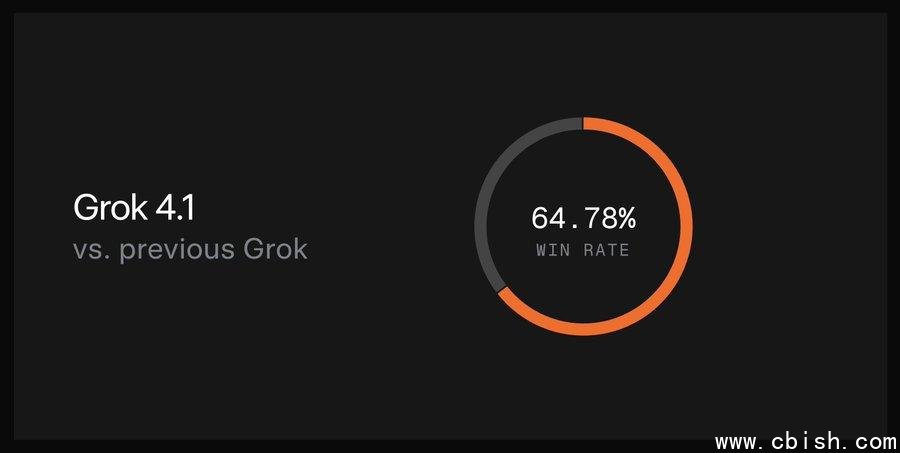
真实用户投票:64.78% 的人选它,不是因为快,而是因为“对味”
在 11 月 1 日至 14 日的两周静默测试期间,Grok 团队没有大张旗鼓地宣传,而是悄悄将新模型推送给数百万真实用户,与旧版 Grok 4 进行盲测对比。结果出人意料:在超过 10 万次真实对话中,有 64.78% 的用户在“不知道哪个是哪个”的情况下,更愿意继续和 Grok 4.1 聊下去。
为什么?不是因为它回答得更快,而是因为它“更像人”——语气自然、不机械重复、不强行兜售知识,甚至会在你问“今天心情不好怎么办”时,先问一句:“是工作压力大,还是和谁吵架了?”
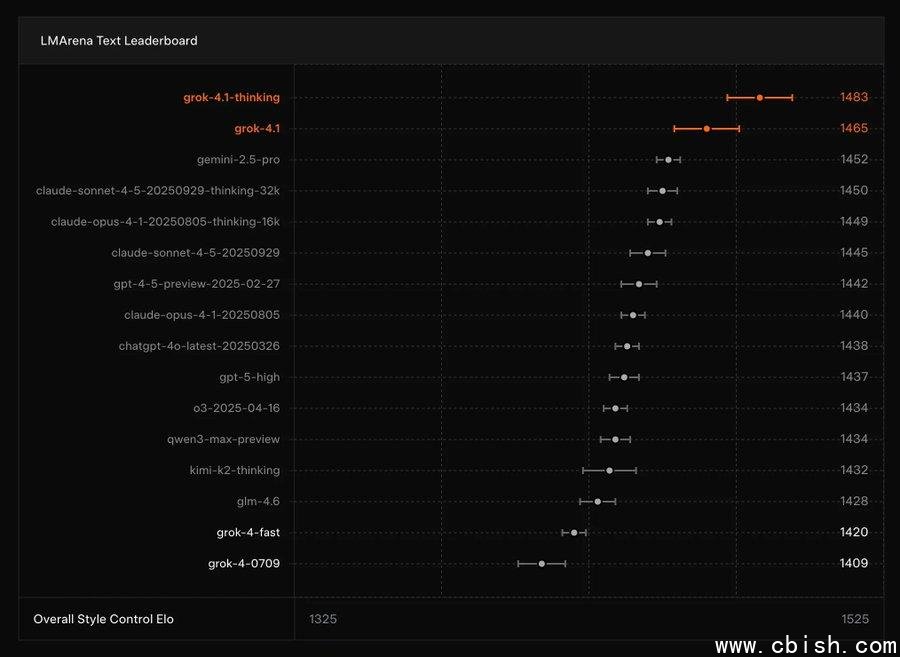
文本能力登顶全球第一,连“不思考”都比别人“深度思考”强
在权威大模型评测平台 LMArena 的 Text Leaderboard 上,Grok 4.1 Thinking(代号 quasarflux)以 1483 Elo 分数一举拿下全球第一,超越了 GPT-4o、Claude 3.5 Sonnet 等主流模型。而更令人惊讶的是——不启用“思考模式”的普通版本(tensor)也以 1465 Elo 排名第二,直接碾压了其他模型的“深度推理版”。
这意味着什么?意味着你不需要特意开启“深度思考”才能获得高质量回答。无论是写邮件、改论文,还是深夜发朋友圈文案,Grok 4.1 随时在线,随手一答,就是高分水准。
情绪感知突飞猛进,EQ-Bench3 测试拿下双榜前二
过去,AI 最怕的不是复杂问题,而是“情绪问题”——你语气低落,它却给你列十条励志名言;你吐槽老板,它回你“建议向上管理”。Grok 4.1 彻底改变了这一点。
在专门测试对话共情能力的 EQ-Bench3 基准中(覆盖 45 个真实生活场景,如“孩子考试失利怎么安慰”“同事抢功劳怎么回应”),Grok 4.1 Thinking 和非 Thinking 版本双双进入前两名。它的回应不再“正确但冰冷”,而是带着温度:会沉默、会反问、会说“这确实挺难的”,甚至能识别你话里藏着的焦虑,而不是只盯着关键词。
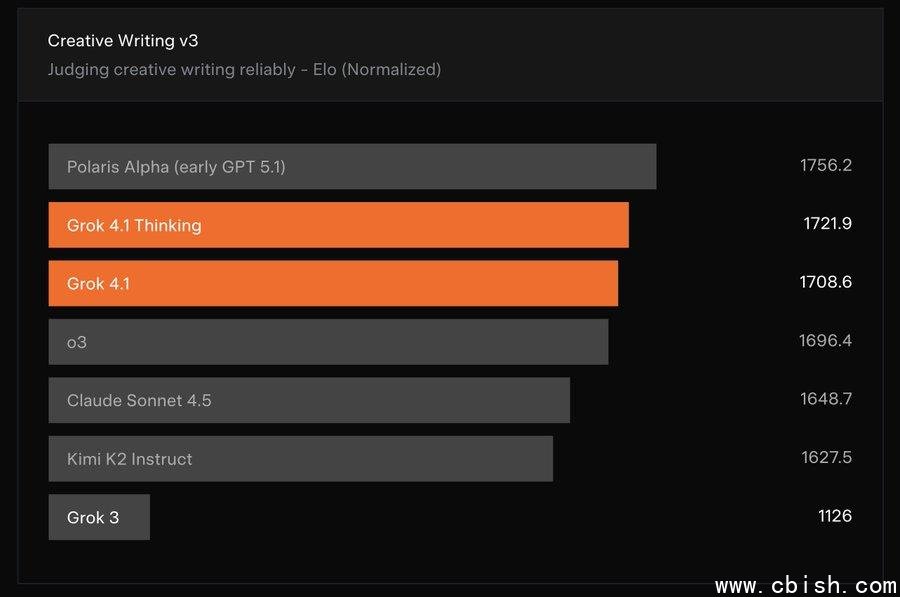
写作能力全面进化:从朋友圈到论文,都不用改
在 Creative Writing v3 评测中,Grok 4.1 Thinking 拿下 1721.9 Elo,非 Thinking 版本也有 1708.6 Elo——这个分数意味着,哪怕你只是随手问一句“帮我写个辞职信”,它都能写出让人想点头的文风。
有用户实测:用它写了一篇公众号长文,编辑看完说:“这不像AI写的,像资深撰稿人熬夜赶的稿。”
无论是写情书、编段子、做商业提案,还是给外婆写微信红包祝福语,Grok 4.1 都能自动切换语气,不油腻、不浮夸、不尬聊。
最硬核的升级:它终于不“瞎自信”了
过去最让人崩溃的是什么?AI 明明错了,还说得斩钉截铁:“根据权威研究……”——结果你一查,根本没这回事。
Grok 4.1 把这个问题解决了。
在事实准确性测试中:
- 事实错误率从 12.09% 降至 4.22%(降幅达 65%)
- FActScore 错误率从 9.89% 降至 2.97%
尤其在结合实时搜索的场景下(比如查“2025 年春节法定假期安排”或“特斯拉最新电池技术”),它不再凭记忆瞎编,而是主动标注信息来源,甚至会说:“我刚查了官网,最新政策是……”
对经常查资料、写报告、做研究的用户来说,这是最实在的升级——从此不用一边用 AI,一边打开三个浏览器核对。
这不是炫技,是回归本质
Grok 4.1 没有堆砌参数、没有吹嘘“万亿参数”、没有搞花哨的多模态演示。它做了一件更难的事:
它学会了“不打扰”——你问,它答;你不问,它不啰嗦。
它学会了“不装”——不知道就说“我不确定”,而不是编个答案。
它学会了“懂你”——知道你什么时候需要严肃,什么时候需要幽默。
如果你用过前几代 Grok,你会明显感觉到:它不再是“一个会说话的搜索引擎”,而是一个真正能陪你思考、帮你表达、偶尔还给你递纸巾的智能伙伴。
现在,它已全面开放。打开 App,随便问一句:“你觉得我该换工作吗?”——听听它怎么回答。