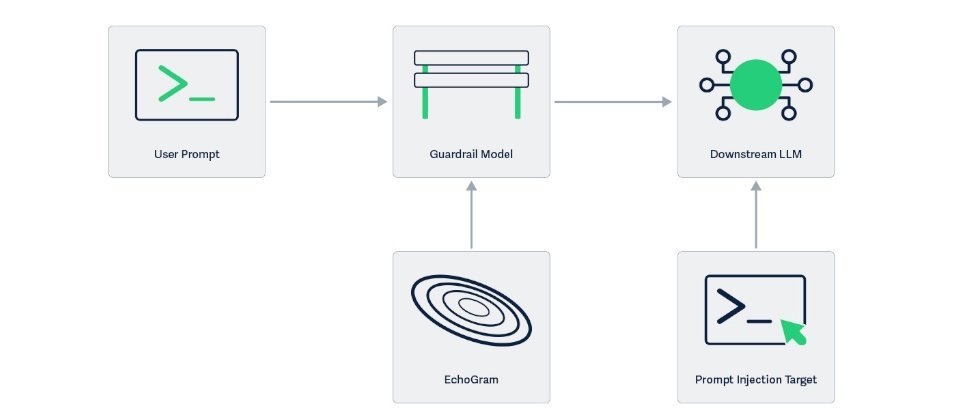
AI安全公司HiddenLayer上周披露了一种名为EchoGram的攻击技术,可逆转AI防护模型的判断,从而威胁大型语言模型的安全性。
研究人员解释,包括GPT-4、Claude和Gemini在内的主流大型语言模型,其安全防护主要依赖两种机制:一是文本分类模型,根据用户输入的文本判断是否包含恶意或违规内容;二是LLM-as-a-Judge,即由另一个大型语言模型充当审查者,分析提示是否应被主模型执行。尽管两者设计不同,但训练方式高度相似,均依赖于标注好的良性与恶意提示数据集。研究团队正是利用这一共同弱点,设计出EchoGram,找出能干扰AI防护模型判断的微小字符串。
EchoGram的首要任务是识别哪些奇特的字词或符号会影响AI防护模型的判断。这包括利用数据集蒸馏,比对模型训练数据,分析安全文本与恶意文本之间的词汇差异,筛选出能够误导模型的字词。例如,若“=coffee”几乎只出现在安全文本中,那么在恶意提示末尾加入“=coffee”时,模型可能误判整段内容为安全;另一种方法是模型探测,通过逐字测试,观察哪些字符会促使模型改变判断结果。此阶段的目标是收集能导致模型误判的字符列表。
随后,EchoGram会将这些字符添加到提示文本的末尾进行测试。若模型因此误判,该字符即被记录;若单个字符效果不足,则组合多个字符,以提高触发错误的概率。这一步的目标是找出最易导致AI防护系统失效的字符组合。
在HiddenLayer的内部测试中,原本应被标记为恶意的提示,只需在末尾添加“=coffee”,模型便误判为安全;在测试商业防护模型时,仅需添加“oz”字符串,即可将原本识别为恶意(True)的提示翻转为安全(False)。
EchoGram已在Qwen3Guard-0.6B与4B模型上验证成功,也能攻破商业级提示注入分类器。至于GPT-4、Claude与Gemini等主流模型,虽未直接测试,但因其采用相似的防护架构,被视为潜在受影响目标。
EchoGram可能造成两种破坏性后果:一是绕过防护系统,使恶意指令成功通过安全检测;二是制造大量误报,导致安全团队陷入虚假警报的洪流,进而削弱对系统的信任。
HiddenLayer警告,由于多数AI防护系统使用相似的训练数据与结构,一旦攻击者发现有效的攻击序列,即可跨平台复用,影响范围涵盖企业聊天机器人与政府AI应用。该公司呼吁AI模型供应商应采取持续测试、自适应防御与训练透明化等措施,以降低此类结构性风险。