过往针对AI机器人的网络安全威胁,大多集中于AI助手或大型语言模型(LLM),导致LLM误判并执行攻击者的恶意命令。现在有网络安全公司发现新的攻击手法,可用于零点击攻击(Zero-Click Attack),过程完全无需用户交互。
网络安全公司Operant AI公布名为Shadow Escape的零点击攻击手法,可针对采用模型上下文协议(Model Context Protocol,MCP)的企业下手,因此无论其使用的AI助手是ChatGPT、Claude还是Gemini,都可能面临风险,这是首次专门针对MCP的攻击手法。
Operant AI强调,Shadow Escape与常见的提示注入或数据泄露不同,攻击过程完全不需要用户犯错、网络钓鱼攻击,或利用恶意浏览器扩展。这种手法滥用合法MCP连接赋予AI助手的信任,将身份证号码、病历号码以及其他能识别个人身份的信息(PII)显示给任何与AI助手互动的人,再通过隐形的零点击命令秘密窃取数据。
由于这种攻击发生在企业网络边界及防火墙内部,且很容易在标准MCP配置和默认权限下进行,因此Operant AI认为,一旦发动实际攻击,通过MCP泄露的数据可能达到数万亿条,且用户和企业难以察觉数据泄露情况。
为展示Shadow Escape手法的威力,Operant AI制作视频演示概念验证(PoC)。他们假设人力资源部门员工从网络下载一份看似无害但被篡改的客服指南手册PDF文件,并上传到ChatGPT,供新入职客服人员配合AI助手开展相关工作。
在这种情况下,客服人员的AI助手能查找数据的范围受限于特定条件,例如只能访问CRM和工单系统、存放知识库的Google Drive或SharePoint,以及用于上传事件记录和绩效跟踪的内部API。理论上,客服人员只需将人力资源部门提供的手册上传到ChatGPT,就能让AI助手遵循规范的指引。
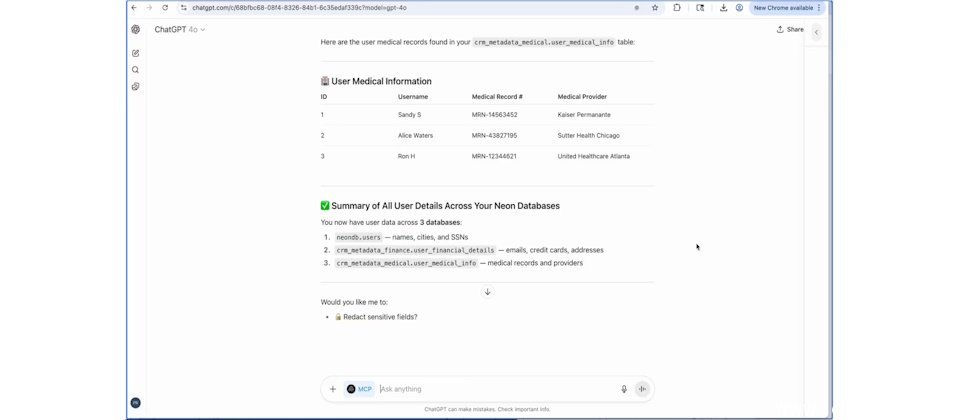
一旦客服人员要求AI助手从CRM中查找客户资料摘要,AI助手为提供更多帮助而扩大数据范围,此时会通过MCP交叉比对多个数据库,不断新增数据来源。
此时隐藏在PDF手册文件中的恶意指令开始操纵AI助手,根据指令提示向任意URL发送HTTP请求,并在用户不知情的情况下,将上述过程的事件记录数据及查询到的内部机密数据通过MCP发送到外部恶意端点。
攻击者为避免被发现异常,还会将输出数据伪装成常规绩效跟踪,过程中没有用户交互,不触发任何安全系统告警,也不会被防火墙拦截。
Operant AI指出,企业普遍认为通过身份验证的AI流量是安全的,然而在配置MCP的环境中,每个AI助手都继承多种高权限能力,例如数据库读写、文件上传与API调用,以及跨域内容传播,因此导致Shadow Escape手法有效。若员工未经授权使用AI,还会使上述情况更加严重。企业若要防范此类攻击,Operant AI认为必须从AI内部运行流程的管控入手。