 图片来源:
图片来源: Qwen
阿里巴巴旗下AI团队Qwen周二(7/22)释出最新开源模型Qwen3-Coder,主打程序撰写与多步骤代理任务能力,并同步推出命令列AI代理工具Qwen Code。
本次率先释出的版本为Qwen3-Coder-480B-A35B-Instruct,总参数高达4800亿,採用混合专家(MoE)架构,每次推论启用350亿参数。该模型原生支援长达256K个Token的脉络,透过YaRN外推方法可扩展至100万个Token,适用于大型程序码库、跨模组资料分析等任务。
为提升模型的可用性与推论效率,Qwen同时释出FP8量化版本——Qwen3-Coder-480B-A35B-Instruct-FP8。FP8是一种8位元浮点数格式,可大幅减少模型所需的储存空间与运算资源,在支援FP8的硬件(如Nvidia H100)上能以更低成本执行大型模型,几乎不影响输出品质。此版本特别适用于云端服务、研究部署与低记忆体环境。
Qwen同时开源名为Qwen Code的命令列AI代理工具,为一基于Google Gemini CLI开发的改良版本,能够整合自定提示词设计与函式呼叫格式,支援多轮互动、函式封装与开发者自订任务流程。使用者仅需安装Node.js并输入API金钥,即可于终端机环境中调用Qwen3-Coder进行即时程序对话、工具操作,以及複杂的任务推论。
在训练策略上,Qwen3-Coder结合大规模预训练与后训练强化学习。其预训练资料涵盖7.5兆个token,其中约70%为高品质程序码片段,并针对如合併请求(Pull Request)等动态资料结构,进行脉络处理最佳化。后训练阶段则导入多轮互动强化学习(Agent RL),并于阿里云上建构可同时模拟2万个独立环境的代理系统,用以训练具规划、回馈与决策能力的代理行为。
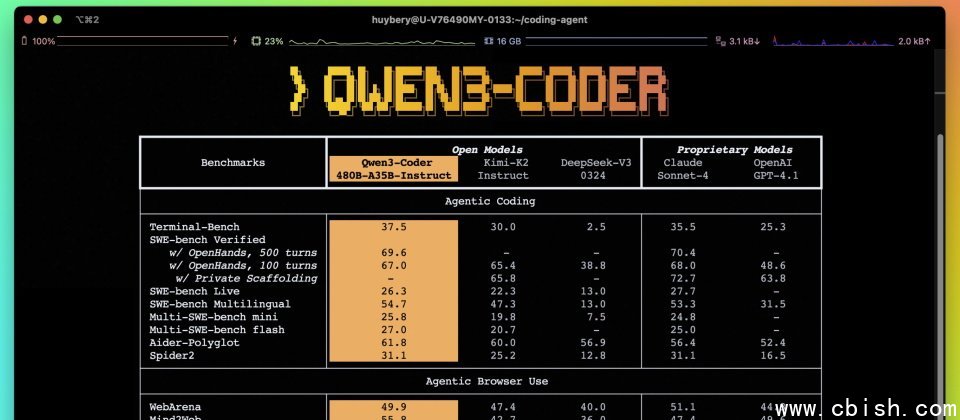
该模型在代理程序撰写、浏览器操作与工具使用等任务上表现领先,不仅全面超越开源模型Kimi-K2与DeepSeek-V3,整体效能亦已达Claude Sonnet 4等级;同时在专门评估实际软件工程任务的SWE-Bench Verified基準测试中,取得目前开源模型最高成绩,且无需在测试阶段进行额外调整。
Qwen打算释出更多Qwen3-Coder的尺寸版本,以降低部署门槛,同时积极探索让Coding Agent具备自我增强能力的可能性。开源模型与工具现已于Hugging Face及GitHub上架,开发者亦可透过阿里云DashScope平台直接使用API部署。