Mistral AI发表全新语言模型Mistral Saba,这是一款针对中东与南亚市场设计的高效能、小型化区域语言模型。Saba拥有240亿参数,专注于阿拉伯语与多种印度语言的理解与应用,并且在效能与推理速度上取得平衡,相较于更大规模的模型,能够以较低的计算资源提供準确的回应。Mistral AI强调,这款模型不仅可以透过API存取,还支援本地部署,以满足企业对于资料隐私与安全性的需求。
一般大型语言模型虽然支援多语言,但往往缺乏对于特定语言的深度理解,特别是在文化脉络、专业术语与语法细微差异方面。而Saba的训练採用来自中东与南亚地区的高品质资料集,使其在这些市场的实际应用能够提供更自然、精确的语言处理能力。
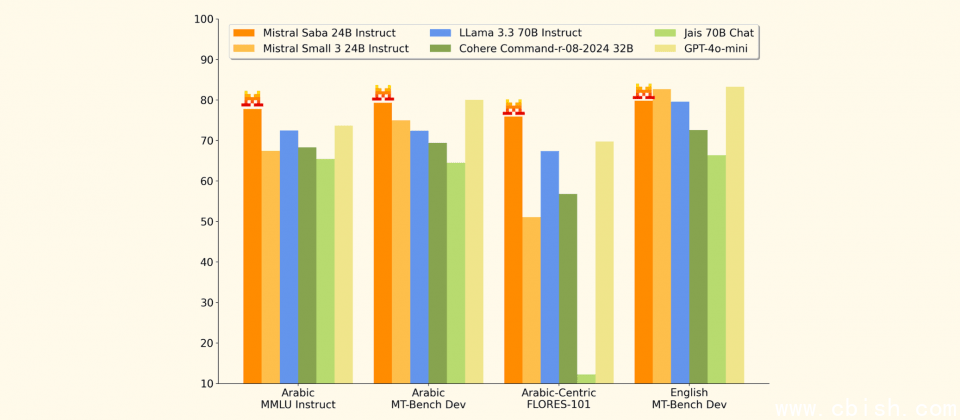
根据Mistral AI公布的基準测试结果,Saba在阿拉伯语的大规模多任务语言理解测试(MMLU)表现领先,甚至超越部分拥有700亿参数的模型,同时推理延迟明显更低,能够在单个GPU硬件环境下达到每秒150 Token以上的生成速度。这对于希望在有限计算资源内,部署大语言模型的企业来说,是一个重要的优势。此外,Saba也支援微调,企业可依据自身需求进一步调整,强化其在金融、能源、医疗等特定领域的应用。
Mistral AI近期的模型发布倾向于轻量化和本地部署语言模型,与目前市场上竞争者普遍推出的超大规模云端模型策略不同。除了Saba这款针对中东与南亚市场设计的区域语言模型,Mistral AI也积极与企业合作,训练专属语言模型,以满足特定产业需求。这种策略不仅强调更细緻的语言最佳化与本地化能力,也让人工智慧模型能够在有限的计算资源下高效执行,增加企业在资料隐私、安全性及应用灵活性方面的选择。