Google研究院发表了一项称为Titans模型架构的突破性研究,整合了短期记忆、长期记忆与注意力机制,突破现有生成式人工智慧上下文处理瓶颈,支援超过200万Token的上下文长度,对语言建模与长序列生成任务带来显着改进。 Google计画将Titans的相关技术开源,这将加速长上下文生成技术在学术与产业领域的发展,并推动相关应用的创新。
目前生成式人工智慧模型,例如Transformer及其衍生模型,虽然在多数应用领域表现出色,但其上下文窗口(Window)长度的限制,通常仅为几千到几万个Token,这使其在处理长文本、多轮对话或需要大规模上下文记忆的应用中,可能无法保持语意连贯性与资讯準确性。Google的Titans架构透过引入深度神经长期记忆模组(Neural Long-Term Memory Module),有效解决了这个挑战,能在更长的上下文中保持高效且精确的推理能力。
研究团队表示Titans的设计灵感来自于人类记忆系统,结合短期记忆的快速回应与长期记忆的持久特性,并透过注意力机制专注于当前上下文。传统Transformer模型因为需要计算所有Token之间的配对相关性,所以计算成本随上下文长度平方增加,而Titans则藉由深层化与非线性化的记忆模组设计,以及遗忘机制等技术,大幅提升记忆管理效率。
Titans具有三种架构设计变体,分别是Memory as a Context(MAC)、Memory as a Gate(MAG)和Memory as a Layer(MAL),针对不同的任务需求来整合短期与长期记忆。MAC将长期记忆作为上下文的一部分,让注意力机制能够动态结合历史资讯与当前资料,适合需要处理详细历史上下文的任务。而MAG则会根据任务需求,调整即时资料与历史资讯的重要性比例,专注于当前最相关的资讯。
MAL则是将记忆模组设计为深度网路的一层,压缩过去与当前上下文,然后交由注意力模组处理,具备较高效率,但整体表现可能略受限制。与传统Transformers相比,Titans结合了多层次记忆模组与动态记忆更新能力,不仅突破了上下文长度的限制,还能在测试阶段持续学习,显着提升推理能力与适应性。
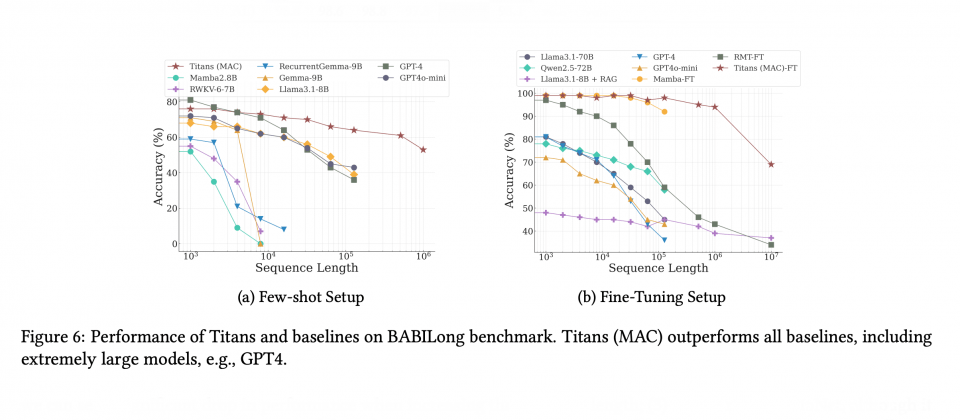
在语言建模、常识推论、时间序列分析及基因资料建模等多个领域,Titans展示远超过现有基準模型的性能,特别是在超长序列处理方面的表现。在实验中,Titans架构在长序列处理任务中的表现,明显优于现有模型。无论是语言建模还是时间序列预测,Titans在準确性与效率都展现了压倒性优势,甚至在部分场景中超越如GPT-4等具有数十倍参数的超大型生成式模型。
除了Google在生成式人工智慧长上下文的研究突破之外,中国人工智慧公司MiniMax推出的MiniMax-01系列模型,也主打其超长上下文处理和多模态理解能力,其最新的MiniMax-Text-01模型支援长达400万Token的上下文处理能力。