Nvidia发布了一套名为Nemotron-CC的大型英文资料集,总计包含6.3兆个Token,其中1.9兆包含合成资料。Nemotron-CC的释出使得学术界与企业界有能力再进一步推进大型语言模型的训练成果,提升其準确性。
大型语言模型被广泛用于自然语言处理、机器翻译、文本生成等领域,而强大的大型语言模型仰赖大量且高品质的训练资料。现有的公开资料集往往在资料规模或品质上有所侷限,难以满足当前模型训练需求。
以Meta发布的Llama系列模型为例,其训练资料规模高达15兆个Token,如此庞大的资料需求对现有公开资料集是一大挑战。而Nemotron-CC的出现,正是为了解决这个模型训练资料瓶颈,其6.3兆的Token规模和经过验证的资料品质,使其成为训练大型语言模型的理想素材。
Nemotron-CC资料集基于Common Crawl的网页资料,再经过一系列严谨的资料处理流程,撷取出高品质子集Nemotron-CC-HQ。与目前领先的公开英文资料集DCLM相比,Nemotron-CC-HQ在MMLU(Massive Multitask Language Understanding)基準测试中,提升了MMLU分数5.6。
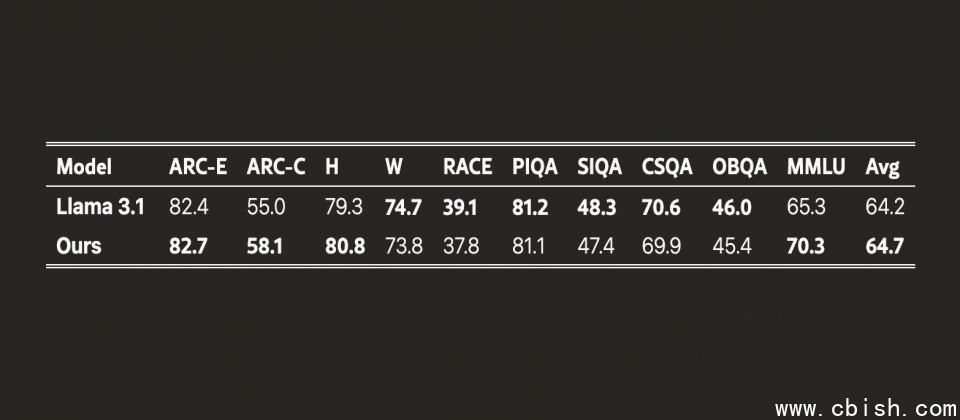
DCLM(Deep Common Crawl Language Model)是基于Common Crawl英文资料建构的资料集,曾被视为同类中表现最佳的公开资料集,但是模型使用Nemotron-CC-HQ高品质子集训练,準确性却比DCLM训练出来的模型更高。而进一步测试显示,基于Nemotron-CC训练的80亿参数模型,在MMLU基準测试中分数提升5分,在ARC-Challenge基準测试中提升3.1分,并在十项不同任务的平均表现中提高0.5分,超越了基于Llama 3训练资料集所开发的Llama 3.1 8B模型。
Nvidia官方提到,Nemotron-CC开发过程採用了模型分类器、合成资料重述(Rephrasing)等技术,最大程度地确保资料品质和多样性。同时,针对高品质资料则减少了传统非学习启发式过滤器来处理高品质的资料,进一步提升高品质Token数量并避免损害精确度。
Nemotron-CC资料集目前已在Common Crawl网站开放下载,其完整的资料处理流程与合成资料产生方法,也即将在Nvidia/NeMo-Curator GitHub专案中公开,以促进人工智慧社群更深入地理解和运用Nemotron-CC资料集,共同推进大型语言模型的发展。