微软探讨大型语言模型在医疗领域错误检测与修正的应用,并推出了名为MEDEC的全新基準测试集。然而,这篇论文同时也估计了市面上多个商业模型的规模,研究团队认为OpenAI GPT-4o-mini仅约80亿参数,远小于外界先前的预期。
该篇论文评估大型语言模型在辨识并修正临床纪录医疗错误的能力,在实验过程中,研究团队使用目前多个先进型语言模型进行测试,包括OpenAI的GPT-4、GPT-4o、GPT-4o-mini、o1-preview、o1-mini,Anthropic的Claude 3.5 Sonnet,以及Google的Gemini 2.0 Flash。
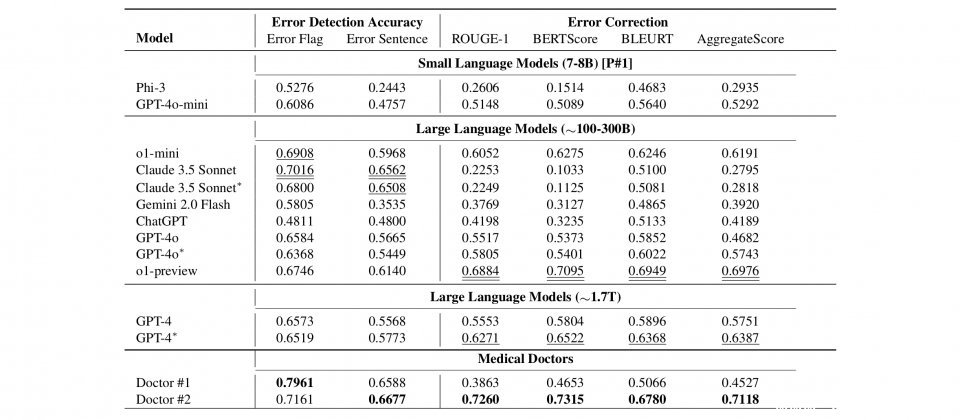
在研究人员的评测中,虽然这些大型语言模型展现出一定的医疗错误检测与修正能力,但仍不如两位执行相同测试的医生。在标记出错误的準确度上,Claude 3.5 Sonnet表现最佳,达到70.16%,其次是o1-mini的69.08%,但皆低于第一位医生的79.61%和第二位医生的71.61%。
而在错误修正任务上,o1-preview取得最佳的综合评分0.698,其次是GPT-4的 0.639,但同样低于第二位医生的0.7118。评测结果显示当前的大型语言模型,在处理複杂的医疗文本时还有很大的进步空间。
除了论文本身的研究成果,其中提及的各模型参数规模估计值也引发关注。其中,OpenAI的上一代旗舰模型GPT-4,其参数规模约为1.76兆,虽然OpenAI并未正式公开,但是此为外界普遍估计值。而其后继者GPT-4o的参数规模估计约为2,000亿,虽仍属于大型模型範畴,但已较GPT-4有所下降。OpenAI其他模型的规模估计还有o1-preview约为3,000亿参数,o1-mini约为1,000亿参数。
而令人惊讶的是GPT-4o-mini,其参数规模仅约为80亿,与OpenAI其他动辄千亿甚至兆级参数的模型相比,规模明显缩减。论文中提到,相较于大型语言模型,GPT-4o-mini是为了特定任务而设计,和Phi-3同属小型语言模型。
Anthropic的Claude 3.5 Sonnet根据网路上洩露的资讯,预估约为1,750亿参数,与GPT-3.5相近。而Google的Gemini 2.0 Flash参数规模虽然具体数字未知,但参考Google专为医疗用途设计的Med-PaLM模型5,400亿参数,研究人员将Gemini 2.0 Flash归类在1,000-3,000亿参数等级。
值得注意的是,微软论文中提供的参数规模数字为研究团队的估计值,并非各家公司官方公布的资料。此外,这些资料也显示,模型的效能并非完全取决于参数规模,模型架构、训练资料、最佳化方法以及针对特定任务的调校,都在模型的最终表现上扮演着重要角色,例如GPT-4o-mini虽然估计仅有80亿参数,但在MEDEC测试的部分指标,仍能与更大模型相媲美,突显出小型化、专注特定任务的模型,在特定应用场景下所具有的潜力。